![]()
![]()
M. WITTLER and L. ARAB
Klinische Institut für Herzinfarktforschung, Bergheimer Strasse 58, 6900, Heidelberg 1, Federal Republic of Germany.
Introduction
The need for a common food coding system has been recognized in the development of a proposal for a merged European food composition data base. Such a proposal provided an opportunity for the designing of a coding system which could assist nutritionists, dietitians, epidemiologists and food technologists in Europe in their international comparisons and in the referencing and sharing of the limited resources of available data on foods, their composition and their intake in various populations.
The coding system would aim to facilitate use of foreign tables and help bypass translational difficulties. It should be capable of assisting in food identification, encoding and searching for descriptive information. It should also enhance comparability of nutritional surveys within and between countries. Finally, it should aid in the exploration of associations between eating behaviour and disease risk.
Development of Eurocode
The first step in the development of a widely acceptable Eurocode was made through the development, circulation and discarding of successive drafts. In 1981 an expert group of the Federal Health Office in Berlin undertook the task of developing a standardized national food coding system for the Federal Republic of Germany. Some members of this committee believed that a standardized system would also be useful for Europe in general and began to draw upon the experience in developing a national code and extending this in a framework for Europe. The commission changed in profile and included members from Holland, Sweden, Denmark, France and Federal Republic of Germany. A first draft of the Eurocode was circulated in December of 1984 at a meeting at the European Community Headquarters in Luxembourg. Twenty-six main food groups structured in an alphanumerical strictly hierarchical form were suggested. The French representatives were influential in demolishing the idea of an alphabetical and English-based code. A new draft of a numerical code was circulated in January 1985 and discussed in detail at a three day coding workshop in February 1985 in Heidelberg. Twenty-seven individuals representing 15 countries attended and agreements on 14 major food groups was achieved. These can be found in Table 1. The draft was tested against national food table entries, difficulties documented and semantic problems overcome by person to person contact and extensive description. Subsequent to this workshop a meeting of the Federal Health Office Commission was held and the idea of a system with three separate components was put forth. This is described later. New drafts were circulated and responses from various groups were worked into a new draft put forth in May 1985 at a joint Eurofoods/Infoods meeting held in Heidelberg. Comments and critique between May and August 1985 were collected from a working group and discussed at a workshop at the Norwich meeting described later in this report. Since then two further rounds of exchange on minor details have been completed and incorporated.
Table 1. Eurocode: primary food groups.
| 1. | Milk, milk products and dishes |
| 2. | Eggs |
| 3. | Meat |
| 4. | Poultry |
| 5. | Fish, molluscs, reptiles and crustaceans |
| 6. | Oils and fats |
| 7. | Grains |
| 8. | Pulses, seeds, nuts and kernels |
| 9. | Vegetables |
| 10. | Fruits |
| 11. | Sugar |
| 12. | Beverages (except milk) |
| 13. | Miscellaneous, soups, sauces |
| 14. | Foods for special nutritional use |
The coding system
The current design for a coding and descriptor system involves two independent food codes and a standard set of variables for supplemental descriptions of foods. In diagram I the basic form of three components are illustrated. Code 1 is an unstructured sequential numbering of all foods available in Europe. Eurocode 2 is a semi-hierarchical, semi-informative code involving three to four fields of information for use in cross-referencing food groups between countries and bypassing translational problems. The agreed 14 basic food groups comprise the first field and a developing set of subgroups, the second field, of Eurocode 2. The third and fourth fields differ from country to country. Eurocode 3 will be a descriptor system, that is a set of parameters for completely describing foods or dishes (mixed foods), their characteristics and their methods of preparation.
Diagram 1. Eurocode system design.
| CODE ONE | 1, n + 1 | non-informative, multilingual list of European foods with a unique code number |
| CODE TWO: field indiv. | |||||||||
| 1 | 2 | 3 | 4 | ||||||
| main group | sub group | national items | variant |
| CODE THREE: | A123, B24, C1, D47 | Descriptor system, a set of variables considered necessary to describe a food for nutritional use | |
A - preparation B - packaging C - form | |||
Eurocode 2
The Eurocode 2 component of the coding system is meant to provide in a food-group-oriented structure and a short numeric system a unique identifying code for each individual food, with no aggregation into generalized groups and no multiple code for the same food. Along with these premises (see table 2), the location of foods should be possible for persons without special nutritional, botanical or food technological knowledge. Flexibility for future expansion to include new foods and new food combinations is essential. The structure should avoid preference for any particular language or eating behaviour. The coding system must incorporate mixed foods, that is foods with more than one component into the main food group of their basic ingredient, not as a separate group of mixtures.
Table 2. Premises for Eurocode 2. A practical code for intake assessment and table cross references.
Incorporating mixed foods integrally with natural foods or unprocessed foods (because the intake form is regularly as a mixture and many hypotheses are directed at the food as consumed).
A system in which the foods are easily located. A system whose usage does not require practical food knowledge (so that no extensive training in use is needed).
A code in which no detail in food identifying information reported by the subject is disregarded or aggregated (even if nutrient compositional data is not yet available).
A brief numeric code for each food (since alphanumeric systems show preference for a single language).
A system with only one code per food or dish. (The advantage for the coder is that there is no need to decide which one is which. An alphabetical index list will help with the problem of locating foods).
A food group oriented system to enable international food comparisons.
A code open for new developments in the food field as well as for new industrial products and for new botanical and zoological hybrids.
A food-group oriented structure was selected to support the desire that entries or typical intakes within a country be readily and exclusively aggregated into the commonly agreed upon major food groups. A short numeric system was chosen for aesthetic reasons and to avoid language preferences. Numeric systems for coding will also bypass the need for skilled typing in the food coding and entry process.
A unique identifying code for each individual food is foreseen, whether or not nutrient information is available, in an attempt to preserve information collected in national surveys instead of deciding in advance what foods or food groups are allowable and coding according to pre-arranged aggregates. No aggregation means that no information is lost in the coding process.
Multiple codes for the same food were also decided against. That is, mixed foods do not have two or more numbers, with positions in multiple food groups and subgroups. The reason for this is that it would confuse later comparisons of groups and make the programming much more complicated. The size of the code is also more compact with this option. The alternative decision would have extended the code endlessly. It would also have made the programming for cross-referencing multiple codes and combining intake information extremely tedious and inefficient.
Another advantage of a single code for food is that the coder does not have to decide under which code a given food will be indexed. And the potential complicating factor of the sum of intakes from food groups yielding more than the total consumed amounts is bypassed.
This particular code is designed for general use. It is not for specialists with specific technical knowledge. It is thought to be a usable resource for all individuals coding surveys, using intake studies or searching through foreign food tables.
A major problem in developing the code is the placement of mixed foods. The simplest solution is generally to put them in a separate group and avoid most of the effort of arranging them in primary food groups. However, within Europe they represent a major portion of foods eaten. Additionally, important physiological differences are to be expected between consumption of simple foods and mixed foods within the groups of their major ingredient. The design incorporates an identifying digit (a preliminary zero) to indicate mixed foods within a group.
These three to four fields are separated by a decimal point. The first field is one or two digits long, representing the numbers 1 to 14 of the agreed upon major food groups. The second field is one to five digits long, the first digit includes the zero in case of marking a mixed food-dish. The third field is a sequential numbering of items relevant within the subgroups to a certain survey or food table. Third field code values will differ from country to country. This is also true for the fourth field, which is used only in those cases in which variations of third field foods exist such as various recipes for the same dishes.
An example of its application for Hungarian Goulash would be 3.05.17.3. The 3 is for meat and meat dishes, .05 for pork dishes, and 17 standing for the 17th type of pork dish in the table of a particular country. The final three implies that three recipes or variations of this dish exist, and can be found in the recipe file.
Two design features have been incorporated to simplify food identification. One is a heading zero as a mixed food marker in the second field. All codes with zeros refer to foods which are composites of more than one basic food. The second is the systematic availability of codes in field two and three for designation of another similar food (code = 1) or an unspecified food of that group (code = 2).
As previously mentioned, Eurocode 2 is meant to enhance and facilitate the utilization of foreign food composition tables. Examples of three uses of the basic structure are the comparison of the distribution of foods in main Eurocode groups in various tables (Table 3), a comparison of food entries for a given subgroup in various tables (Table 4) and the comparison of the nutrient composition in different tables for the same food groups (Table 5).
Table 3. Percentage distribution of foods, dishes and food products from various food tables according to main Eurocode groups.
| 1. | Milk | 8.0 | 10 | 10 | 6.8 | 8.6 | 11 | 6.1 | 11 | 9.2 | 5.9 | 5.4 |
| 2. | Eggs | 0.8 | 1 | 1.6 | 0.5 | 0.9 | 1.8 | 2.3 | 1.5 | 0.4 | 1.2 | 1.7 |
| 3. | Meat | 19 | 20 | 21 | 21 | 10 | 14 | 16 | 24 | 15 | 13 | 16 |
| 4. | Poultry | 3.6 | 2.5 | 3.4 | 2.3 | 1.0 | 6.1 | 6.6 | 6.6 | 1.8 | 3.7 | 4.0 |
| 5. | Fish, molluscs reptiles, crustaceans | 11 | 11 | 5.1 | 9.7 | 3.1 | 14 | 5.5 | 13 | 24 | 8.1 | 9.0 |
| 6. | Oils, fats | 3.6 | 5.2 | 4.4 | 0.5 | 2.5 | 2.1 | 2.3 | 2.8 | 2.2 | 1.8 | 4.4 |
| 7. | Grains | 7.4 | 10 | 4.1 | 19 | 12 | 13 | 12 | 10 | 4.4 | 10 | 14 |
| 8. | Pulses, seeds nuts, kernels | 6 | 3.7 | 5.5 | 2.2 | 4.0 | 6.1 | 0.7 | 4.3 | 7.5 | 8.9 | 4.8 |
| 9. | Vegetables | 15 | 14 | 16 | 14 | 14 | 15 | 15 | 6.9 | 12 | 13 | 10 |
| 10. | Fruits | 8.6 | 11 | 10 | 7.3 | 7.0 | 8.0 | 10 | 8.0 | 12 | 13 | 14 |
| 11. | Sugar, sweets | 2.8 | 3.5 | 4.4 | 5.3 | 6.0 | 4.0 | 5.6 | 2.9 | 3.5 | 3.5 | 2.8 |
| 12. | Beverages, (exc. milk) | 7.2 | 5.8 | 9.9 | 5.1 | 7.3 | 4.5 | 8.5 | 7.2 | 4.8 | 12 | 5.4 |
| 13. | Misc., soups, sauces | 6.4 | 1.2 | 4.1 | 2.8 | 10.9 | 1.1 | 4.7 | 1.7 | 2.6 | 4.7 | 6.3 |
| 14. | Special nutr. usage foods | 0.6 | 0 | 0.2 | 3.3 | 11.1 | 0.3 | 1.8 | - | - | 0 | 0.4 |
| n of foods | 503 | 649 | 435 | 393 | 1193 | 375 | 425 | 347 | 227 | 856 | 1100 | |
The Eurocode 2 has been applied to 18 food tables from various countries, and the results stored on a multilingual food name database in Heidelberg. This coding has enabled comparisons of published tables in a number of ways. Three will be represented here: as mentioned above, the distribution of foods by main Eurocode groups; the utility of Eurocode in identifying which food items are available from which tables (Table 4); and use of the code for comparing the ranges of values for similar foods from different tables (Table 5).
Table 4. Food entries from 15 tables for Eurocode 7.8 rice and 7.08 rice products.
7.8: RICE GRAIN/MILLED PRODUCTS
| DENMARK | FEDERAL REPUBLIC OF GERMANY | FINLAND (AHOLA) |
| RICE, FLOUR | RICE STARCH | RICE, WHOLE-GRAIN |
| RICE, PARBOILED, RAW | RICE HALF POLISHED | RICE, POLISHED |
| RICE, BROWN, RAW | RICE UNPOLISHED | RICE, POLISHED BOILED |
| RICE, POLISHED, RAW | RICE POLISHED | RICE, PUFFED |
| FINLAND (VARO) | FRANCE (OSTROWSKI) | FRANCE (RENAUD) |
| RICE | GRAIN BROWN RICE | RICE |
| RICE FEED MEAL | RICE FLOUR | RICE FLOUR |
| RICE, PARBOILED | RICE POLISHED | RICE RAW |
| RICE, POLISHED | RICE COOKED | |
| RICE, PUFFED | ||
| GREECE | ITALY | NORWAY |
| RICE WITH RAW | RICE FLOUR | RICE STARCH |
| RICE POLISHED, ORYZA SATIVA | PARBOILED RICE | |
| UNPOLISHED RICE | ||
| POLISHED RICE | ||
| PRECOOKED RICE | ||
| POLAND | PORTUGAL | SPAIN |
| RICE | RICE GRAIN | |
| RICE FLAKES GUICH | RICE FLOUR | |
| RICE PUFFED | ||
| SWEDEN | NETHERLANDS | UNITED KINGDOM |
| RICE PARBOILED | RICE FLOUR | RICE, BROWN, RAW |
| RICE PARBOILED COOKED | RICE, PARBOILED BOILED UNCLE BEN'S | RICE, BROWN, COOKED |
| RICE BROWN COOKED | RICE, SEMI-POLISHED UNPREPARED | RICE POLISHED RAW |
| RICE POLISHED | RICE, SEMI-POLISHED, AS THICKENER | RICE, POLISHED, BOILED |
| RICE POLISHED COOKED | BROWN RICE UNPREPARED | |
| RICE INSTANT = RICE PARTLY PRECOOKED | RICE, UNPOLISHED BOILED | |
| = RICE PARTLY PRECOOKED COOKED CA 5 MIN | RICE POLISHED UNPREPARED | |
| RICE PUFFED | RICE FLOUR INSTANT NUTRIX | |
| RICE PUFFED ROASTED | RICE BOILED | |
7.08: RICE GRAIN/MILLED PRODUCTS DIS
| DENMARK | FEDERAL REPUBLIC OF GERMANY | FINLAND (AHOLA) |
| FINLAND (VARO) | FRANCE (OSTROWSKI) | FRANCE (RENAUD) |
| RICE PUDDING (RICE WITH MILK) | ||
| GREECE | ITALY | NORWAY |
| BISOTTE PESCATORA | ||
| POLAND | PORTUGAL | SPAIN |
| SWEDEN | NETHERLANDS | UNITED KINGDOM |
| RICE PORRIDGE | RICE KRISPIES | |
| RICE KRISPIES | EGG FRIED RICE | |
| SPICED FRIED RICE BALL-DEEPER., PREP. | FRIED RICE, OTHER THAN EGG | |
| FRIED RICE, IND. STYLE+MEAT-CAN/DEEPFR. | ||
| FRIED RICE, IND. STYLE WITH MEAT AND EGG | ||
| RICE MOUSSE JACKY | ||
Table 5. Nutrient values for the same foods from four different tables.
| EUROCODE | Foodname | Land | Sodium Na mg/100g | Potassium K mg/100g | Magnesium Mg mg/100g | Calcium Ca mg/100g |
| 10.303.0 | Apples | Netherlands | 2.0 | 150 | . | 10.0 |
| 10.303.0 | Apple | Finland | 0.8 | 140 | 6.0 | 7.0 |
| 10.303.0 | Apple | Sweden | 1.0 | 110 | 8.0 | 7.0 |
| 10.303.0 | Apple | FRG | 3.0 | 144 | 6.4 | 7.1 |
| 10.303.1 | Apple unpeeled | Netherl. | 3.0 | 279 | . | 10.0 |
| 10.303.1 | Apple dehydrate water: 2.5% | Sweden | 7.0 | 730 | 22.0 | 40.0 |
| 10.303.2 | Apples dried water: 24% | Sweden | 5.0 | 569 | 22.0 | 31.0 |
| 10.303.1 | Apple sauce - can or glass - | Netherl. | 9.0 | 130 | . | 5.0 |
| 10.303.1 | Apple puree canned | FRG | 2.7 | 114 | 9.8 | 4.4 |
In Table 3 it can be seen that the most heavily represented food groups throughout Europe are groups 3 and 9: meat and vegetables. In the Spanish and Portuguese tables, the group of fish, molluscs, reptiles and crustaceans (group 5) are of primary importance. In the Finnish, the Dutch and British tables, grain products have among the greatest number of entries. To meet these specifications, the above described numeric code with two information fields, and two non-informational fields, was developed. Diagram 2 illustrates the code design. The relative scarcity of information on the components in foods (most tables and databases contain less than 2000 foods, whereas the available products number in tens of thousands) suggests that the search for a particular item has the chance of success. To enable the user of food tables to identify if the item sought, or something similar, is available in one or more of the 18 European food tables, before the effort undertaken to access foreign tables, and translate the entries in the search, a list of food entries in English and native language has been constructed by Eurocode 2 field 2 subgroups. A sample of this for rice and rice products (Eurocode 7.8 and 7.08) can be found in Table 4 for 15 European food composition tables. Here one will find where analyses of brown rice, polished rice, parboiled rice, puffed rice, rice flour and rice starch are available. The rice products in these food tables include mixed foods or dishes such as ‘risotto pescatore’, ‘egg fried rice’, ‘rice mousse Jacky’ and ‘rice crispies’.
Finally, comparison of ranges of values for whatever reasons are important for food table users in the assessment of confidence intervals for the real nutrient value of a given food. Subgrouping similar to the previous example has been undertaken to compare mineral levels. This can be examined in Table 5, for the code 10.333; apples.
Diagram 2. Code 2 design.
| 1 | 2 | 3 | 4 |
1. Main Group (1–14)
2. Specific food at specie level/mixed dishes group
3. Sequential, nation specific list of items
(4. Variations of 3rd field dishes)
The current draft of Eurocode 2 is available on request from L. Arab.
Conclusion
A system has been proposed for merging and cross-referencing foreign food tables and foreign food intake surveys. Compromises were made and inconsistencies tolerated to guarantee general European acceptance of this system, and to keep it relatively simple. It is now hoped that organization of national food composition tables will be structured around these food groups and that intake surveys will store the information by Eurocode classifications to improve national and international comparability just as the ICD (International classification of diseases) has helped surveillance, monitoring and understanding of the etiology of diseases.
L. BERGSTRÖM
The Swedish National Food Administration, Box 622, S-75126 Uppsala, Sweden.
Introduction
The Eurofoods NLG project was established in 1983 at the Eurofoods Workshop in Wageningen. The main task of the project is to collect data related to nutrient losses and gains in the preparation of foods so that factors can be recommended for use in the calculation of the nutrient content of the data bank recipes.
To approach this goal the work of the project has been divided into five subprojects; recipe calculation systems; recipes for ten dishes, analysed and calculated for energy and nine nutrients; NLG research; NLG references and NLG data base. The results achieved depend entirely on the participants' voluntary work as this project has proceeded without any funds.
Recipe calculation systems
Analyses of dishes are rather expensive but the composition of cooked food is needed, e.g. for research into different problems in human nutrition and for nutritional and dietetic treatment of disease. Therefore, calculation of recipes has been used for many decades. A tendency towards standardization of recipes was also noticed at an early stage (McCance & Widdowson, 1940) and standard methods for calculating these recipes were introduced, e.g. by using the percentages of ingredients included in recipes (Merrill, Adams & Fincher, 1966).
Recipe calculation for energy and nutrient content can be performed in several ways and at different levels, as follows: (1) on percentages of analysed raw ingredients in recipes; (2) on percentages of analysed cooked/processed ingredients in recipes; (3) on percentages of raw ingredients, either by calculation of yield for the whole cooked dish or using yield factors to adjust each raw ingredient weight to cooked one; (4) on percentages of raw ingredients, either (a) by calculating yield for the whole cooked dish, adjusting for water content (and fat content) and using NLG correction factors for the whole recipe, or (b) by changing the raw ingredients to analysed cooked ones using yield factors to adjust the raw ingredient weights to cooked ones or keeping the raw ingredients, correcting the weights for water, fat and fatty acids to cooked yield of the recipe and using NLG correction factors to adjust the nutrient content.
These NLG correction factors can be used in different combinations: for a nutrient in each food/ingredient of a recipe; for a nutrient in a group of foods/ ingredients of a recipe, and for a nutrient in the total food/ingredient content of a recipe.
Correction factors can be used at different levels according to cooking methods.
NLG recipe calculation systems on computer can be divided into the following three main groups.
1. Computerized NLG
Only ingredients of a recipe and the yield factor for cooked dish are entered into the computer and NLG correction factors are programmed.
2. Semi-computerized NLG
The ingredients of a recipe are calculated manually according to method 4, mentioned above, and/or the NLG correction factors have to be entered for each recipe.
3. Manually calculated NLG
The computer is used to calculate raw ingredients adjusted to yield of the cooked dish, and the nutritive values are corrected manually afterwards.
Table 1. NLG recipe calculation systems in Europe, 1985.
| Country | Owner | Type of NLG System | Yields after cooking | NLG correction factors for | |||||
| Proximates | Vitamins | Minerals | Ingredients | Groups of foods | According to cooking methods | ||||
| Denmark | The National Food Agency of Denmark | Computerized | x | x | x | x | |||
| Federal Republic of Germany | Federal Research Centre for Nutrition Institute for Economy and Sociology of Nutrition | On computer Dishes calculated with yield factors for weight, energy and nutrients are included | x | x | x | x | X | ||
| Finland | The Department of Nutrition, University of Helsinki | Semi-computerized | x | x | x | x | |||
| Finland | The Rehabilitation Research Centre | Semi-computerized | x | x | x | x | |||
| German Democratic Republic | Zeutralinstitut für Ernährung | None | |||||||
| Greece | Athens School Hygiene Dep. of Nutrition and Biochemistry | None | |||||||
| Iceland | Icelandic Nutrition Council | None | |||||||
| Norway | The National Society for Nutrition and Health | Manually | x | some | |||||
| Norway | Section for Dietary Research, University of Oslo | Semi-computerized | x | some | |||||
| Poland | Human Food and Nutrition Institute Dep. of Nutritive Value of Food | None | |||||||
| Portugal | Institute Nacional de Saude | None | |||||||
| Spain | Instituto de Nutricion (C.S.I.C) | Manually | x | fat | some | ||||
| Sweden | The National Food Administration | Semi-computerized | x | some | |||||
| Sweden | AB Felix | On computer | x | ||||||
| Sweden | AB AIVÓ AB | On computer | x | ||||||
| The Netherlands | Dep. of Human Nutrition Agricultural University | Manually | x | fat | some | ||||
| United Kingdom | MRC Dunn Nutrition Unit | Semi-computerized | x | x | |||||
The borderlines between these groups are not distinct.
As there are so many different ways of recipe calculation, it seemed important to invent the recipe calculation systems in Europe. Only one nutrient data bank owner's system seems to be completely NLG-computerized according to the above definitions and that is the Danish one. At least five countries have semi-computerized NLG systems in Europe. Five countries are NLG-correcting recipes manually and five countries have no NLG system at all. Two systems have only yields after cooking included (Table 1).
At many European laboratories cooked dishes are analysed for nutrients and the results are used as basic information in recipe calculation. Scientists of The Federal Research Centre for Nutrition in Stuttgart-Hohenheim have their own and others' research results in creating yield factors for energy and nutrients to be used in recipe calculation. The European recipe calculation systems have to be further investigated.
Recipe analysis, calculation and correction
Recipes for ten dishes were chosen: spinach soup, mashed potatoes, pommes frites, boiled rice, thin pancakes, roast beef, meat loaf, fried pork, roast chicken and fried cod fillet. People were asked to give information on ingredients and on nutrient content in analysed and calculated dishes. The main problem was that people usually have either analysed or calculated dishes, seldom both.
Dr Bognár in Stuttgart has, as mentioned above, been working on specific yield factors for energy and nutrients to be used in recipe calculation. This work is reported in Berichte der Bundesforschungsanstalt für Ernährung BFE-R--84-04. On the calculations collected Dr Bognár was to use these factors when recalculating the recipes and see if his calculation would be closer to the analysed values than without yield factors.
As the material is rather limited it is difficult at this stage to draw any conclusions. It seems though that the calculation is of less importance than other parameters, therefore calculation of standardized recipes will be performed as a next step and these results will also be compared to nutrient analyses of the dishes.
NLG research
For recipe calculation both food yields and nutrient correction factors are needed. An inventory of laboratories of different administrations, institutes, food industries etc. was compiled in an attempt to find people who are working on NLG and who are interested in collaborating with the project. In this inventory very few laboratories were reached.
NLG references
Laboratories might provide the NLG project with data directly, but there is also the indirect way to get information on nutrient losses and gains: through literature references. The project participants have sent in many references, especially Dr Singer, U.K. As Norfoods members have already collected NLG references it would seem practical to report all references in a joint Norfood/Eurofood publication.
European NLG data base
In order to store the references and NLG information a special NLG data base is needed.
At the Swedish National Food Administration the data processing unit has, in cooperation with the nutrition section, developed a model on behalf of Eurofoods NLG project.
Table 2. European NLG data base questionnaire. Answers from eight individuals.
| Losses of different kind: | |
| Fat left in pan | 6 |
| Drippings etc | 6 |
| Dry matter loss | 1 |
| Factors affecting nutrient content: | |
| Cooking/processing method | 7 |
| Cooking time | 7 |
| Cooking temperature | 6 |
| Temperature profile [Temp=f(time)] | 1 |
| Final internal/centre temperature | 2 |
| Surface temperature in frying | 1 |
| pH | 1 |
| Pressure | |
| Volume-surface ratio | 1 |
| Processing parameters e.g. aerobic/anaerobic | 1 |
| Changes during fermentation | 1 |
| Are you in favour of a common European NLG data base? | 7 |
| Do you know any institute willing to host such a data base? | 3 in FRG |
| 1 in Spain | |
| 1 in Sweden | |
| Nutrients to be reported: | |
| For foods both fresh and prepared/processed | |
Fresh weight | 6 |
Dry weight | 6 |
| In boiling water | 6 |
| In drippings | 6 |
| In left frying fat | 6 |
| Factors to be collected or created on information in the base | |
| Yield factors for weight/edible part | |
| Yield factors for nutrients and energy | |
| Retention or NLG factors in percent | |
| Comments | |
| Financial support is needed | 2 |
| Difficult to prepare a common European NLG system as there are regional differences in the methods of food preparations | 1 |
| Which information should be included? | |
| References: | |
| Author | 7 |
| Title | 6 |
| Journal/book etc | 6 |
| Year | 7 |
| Analyses: | |
| Address of research institute | 1 |
| Method of analysis | 1 |
| General information: | |
| Food/dish | 7 |
| Food group | 6 |
| Amount food cooked in a study | 7 |
| Raw ingredients | 6 |
| Cooked ingredients | 6 |
| Recipes of dishes with good description of edible portions and waste. | 3 |
| Measurements of cooked ingredients included | 1 |
| Food yield by dishes | 6 |
| Amount boiling water added | 7 |
| Amount frying fat added | 6 |
| Type of fat added | 1 |
| Amount salt added | 7 |
The model is on the computer Nord 100 CX, using MIMER Quiry language, but the concept of the model may be transferred to any other computer and language. For developing the model to full scale, another language, e.g. ADA, and a very flexible database management system such as MIMER or ORACLE is needed for the storage and for the retrieval of the huge amount of data. The main purpose of the model is to collect data on nutrient losses and gains in the preparation of foods for creation of NLG factors to be used in computerized recipe calculation systems, but it can also be used as an extended nutrient data base system.
The model is now divided into different objects as foods (coded with Eurocode) with different stages and processes; dishes, recipes; nutrients, nutrient groups; authors, articles = references, results in the references and so on.
Cooking methods and processes can be divided into different procedures with physical, chemical and biological parameters included in order to structure and retrieve the data.
This model can be developed into a computer-based management system of nutrient losses and gains in the preparation of foods but other information can also be added, e.g. interactions between food and/or nutrients and, maybe, in the future bioavailability of nutrients.
Such a system could be used in several ways by people of different professions. German, Spanish and Swedish nutrient data bank owners might be interested in hosting such a base. The main problem is the financial one (Table 2).
Conclusion
It is of great importance that this NLG work should continue and also be extended to other countries. A well functioning recipe calculation system is needed, as many users of nutrient data banks are in the process of creating such systems. Now is the right time to recommend common NLG factors or a recipe calculation system for increasing the compatibility between different nutrient data banks.
For more information, please read the full report: NLG Project 1985 by Lena Bergström and Antal Bognár, available from the author.
References
McCance R.A. & Widdowson E.M. (1940) The chemical composition of foods, London: HMSO.
Merrill, A.L., Adams, C.F. & Fincher, L.J. (1966): Procedures for calculating nutritive values of homeprepared foods: as used in Agriculture Handbook No. 8. USDA, ARS 62-13.
W. M. RAND
Massachusetts Institute of Technology, Laboratory of Human Nutrition, Cambridge, MA 02139, USA.
Introduction
Infoods was organized for the specific task of improving the amount, quality, and availability of food composition data around the world. It is coordinated by a secretariat based at the Massachusetts Institute of Technology in the United States, and supported by the United Nations University, the United States government, private foundations, and the food industry.
Infoods has three major aspects: it is global; it is concerned with the availability of food composition — including access, intelligibility, and suitability; and it is concerned with the quality of food composition data. Infoods is currently involved with setting up networks of people and data, and developing the guidelines and machinery to operate these networks.
Examples of needed guidelines follow consideration of the sequence from food to analytic data on composition to database or table to data usage. Thus, the data generators need to ensure that the necessary data are obtained correctly, the data compilers need to be able to supply the needed data when and where they are needed, in a usable form, and the users need to be able to obtain the data they need, and to be able to interpret them. Carefully formulated and documented guidelines are essential for global consistency and compatibility of such relevant activities.
In order to achieve its goals, Infoods is currently designed around a secretariat and three working groups.
Data quality
This group is addressing the problems of food composition data to ensure that the databases and tables are accurate, i.e. how data quality can be assessed and improved. David Southgate is coordinating this activity with the assistance of Heather Greenfield.
Terminology and nomenclature
This group is concerned with making food composition data universally intelligible, in terms of the names of the foods and nutrients, and also by recommending what additional information should be collected and made available. This activity is being directed by Stewart Truswell.
Information systems
This group, directed by John Klensin, is exploring how modern computer technology and information theory can best link food composition data and the users.
The secretariat coordinates the working groups in addition to carrying out other activities necessary to the task of improving food composition data. These activities range from preparation and distribution of a global directory of food composition tables to the forging of links between, and encouraging and helping to organize, regional organizations such as Eurofoods, which are concerned with food composition data.
In summary, Infoods is a global organization concerned with those aspects of food composition that are universal. It can only succeed if it is able to rely on strong regional organizations such as Eurofoods. The problems that are being faced are large. However, it is of a critical and growing importance that they be attacked and solved.
D. A. T. SOUTHGATE and H. GREENFIELD
Head, Nutrition and Food Quality Division, AFRC Institute of Food Research, Colney Lane, Norwich, UK and Senior Lecturer, Department of Food Science and Technology, University of New South Wales, P.O. Box 1, Kensington NSW 2033, Australia.
Introduction
The Infoods (International Network of Food Data Systems) project to produce a set of guidelines for the production, management and use of food composition data was conceived at the Infoods planning conference held in Bellagio (Italy) in January 1983. The meeting agreed that many problems existed with food composition data worldwide. Data were scarce for many foods and many nutrients and those facts available were of uncertain quality. Moreover, there were difficulties in using existing data sets together because of their different modes of expression, different formats and different systems for food nomenclature. These problems posed significant constraints to the effective and accurate use of food composition data, giving rise to major barriers in carrying out and interpreting nutritional studies based on measurement of food intakes (Rand & Young, 1983).
The Infoods guidelines are based on Southgate's (1974) published guidelines for the preparation of tables of food composition which originated as a working paper presented at a meeting of the Group of European Nutritionists held in Zurich, 1972. This group was interested in national food composition tables and in the future possibility of a set of European food composition tables. Some years later Eurofoods has the same preoccupations, but with an emphasis on computerized databases as well as printed tables.
Work began on the Infoods project late in 1983 and a first draft was the subject of perusal and amendment by a group of experts who met at the invitation of Infoods in Washington in January 1985. The revised draft will be circulated to the IUNS Committee 1/10, ‘Techniques for measuring the value of foods for man’ (Chair: D.A.T. Southgate) and the IUFOST Commission on Food Safety and Composition (Chair: A.E. Bender). It is anticipated that the published manual will be available in 1987.
The Infoods guidelines have the following objectives: (1) to improve the volume and quality of food composition data; (2) to improve the comprehensiveness and quality of food composition data systems, and (3) to improve the compatibility of food composition data systems.
To meet these objectives the guidelines attempt to outline guiding definitions, principles, objectives and criteria in the production, management and use of food composition data, and also to outline the responsibilities of all concerned with such data, including policy-makers, managers and compilers of data systems, food analysts, educators and users. The guidelines are not standards since these cannot be imposed on individual nations or on individual scientists. It is expected, however, that the guidelines will be widely followed and that this common usage will result in a greater harmonization and compatibility of food composition data systems worldwide.
Table 1. Areas covered by Infoods guidelines for the production, management and use of food composition data.
| • | Initiation and organisation of a food food composition data system program |
| • | The selection of foods for inclusion |
| • | The selection of nutrients for inclusion |
| • | Sampling of foods for analysis |
| • | Analytical methods |
| • | Quality assurance of analytical data |
| • | Format of a food composition data system |
| • | Use of a food composition data system |
The text draws heavily on US and UK experience of producing and managing food composition data and on Australian experience of producing data for a national data system. The text follows all the steps involved in an ideal food composition data system program from the initiation of such a program through to the use of the database (Table 1).
Figure. Stages of the data system program.
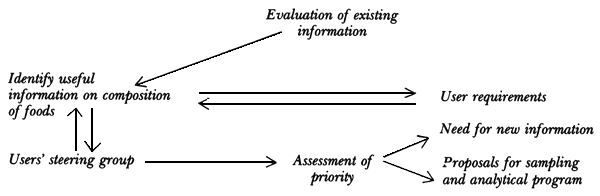
Organization of a food composition data system program
The stages of an ideal program can be set out systematically (see Figure). This structure assumes that a body of information on the composition of foods consumed in the country or region already exists. This is the usual situation even in countries where there are no formal national tables of food composition. The first stage is therefore to examine this information.
Reviews of existing information
The information, both published and unpublished, is evaluated considering the information as data sources. It is then considered in relation to user requirements and provides indications of what new information is required. This in turn provides the basis for proposals for sampling and analytical programs. In most countries it will be necessary at this stage to define priorities and this will require further input from the users of the data systems.
Sampling and analytical programs
These programs need to be considered as an entity both from the viewpoint of data quality and also because the resources required for sampling and analysis need to be estimated together.
In developing the sampling plan, a considerable range of inputs is essential and the compilers need to consult widely. In many countries this stage involves assigning an element of the program to a contractor. If this is done it is essential that the compiler ensures that the contractor is aware of user requirements and the quality standards that have been set for data entering the system.
Sampling and analytical programs are most conveniently focused on specific foods or groups of foods. In placing contracts, focusing on specific food groups also defines the experience required in groups invited to tender for the contracts. Resource requirements will be determined by the proposed timescale for the work and logistical factors need to be considered very carefully. Once all these factors have been assessed it is possible to cost the different program sections and submit this for budgetary approval.
Supervision of analytical program
In principle, the concept of data quality should be built into the analytical procedures and the representation of the analytical interests on the Users' Steering Group will ensure that the analysts are aware of the detailed requirements of users. Nevertheless, it is useful to review analytical programs regularly throughout the work to reinforce the overall objectives of the analytical work, that is, the construction of a food data system.
Evaluation of analytical reports
The output from the analytical laboratory provides an input at the data source level and the values are subjected to initial evaluation ideally in discussion between compilers and analysts to ensure consistency in the data and to examine difficulties that arose during the execution of the work.
In practice difficulties are inevitable and often require those involved in sampling or analysis to respond rapidly and to depart from the formal protocols. It is vital that the compilers are fully aware of these changes.
Compilation of the data bank level
Once sufficient information has accumulated to compile the data bank it is desirable to initiate reviews by the Users' Steering Panel and by external specialists in a commodity or food group. The users' review serves two major purposes, first, it provides an assessment of whether the objectives defined by the users are being met and, second, it provides a means of managing the progress of the program.
The external review serves as a conventional peer-review and ensures that the data being acquired within the program are compatible with specialised knowledge for the commodity or foods (which may not be nutritionally orientated). Where proprietary products are involved it is desirable to submit the data to the manufacturer for comment. This will serve to identify inconsistencies in relation to the manufacturers' quality control data and to indicate whether the samples analysed were representative of normal production.
Compilation of the user database
Compilation refers to the management of data through the various levels of the data system, starting with the acquisition of the sources of the analytical values, the entry of values into the data system, the conversion of values to systematic modes of expression, the objective evaluation of values against a series of criteria, and finally the selection or amalgamation of values in the production of the user database. The compilation process is the point at which the direct analytical method and the indirect literature-based method of preparation merge (Southgate, 1974).
This requires close liaison between the Users' Steering Group and the compilers. A review by users of sections of the database as they are prepared is highly desirable.
These reviews enable the compilers to bring to the attention of future users of the database problems regarding format, evidence of inadequate data, or that critical scrutiny of existing values has indicated the need for further analytical work. As the database nears completion pilot trials of its operation become desirable and these can be organized through the Users' Steering Group.
Operation of the database
Once the database comes into operation a series of operational studies are desirable. Although studies designed specifically to test the system are valuable the real tests come in regular use, and provision should be made to collect and collate experiences in use, e.g. particular difficulties or inconsistencies. Errors need to be centrally recorded so that the database can be corrected. Maintenance of the database needs to be seen as a continuous development leading to improved usage. It is also desirable to include some provision for periodic revision with a permanent Users' Group that considers extension and revision against the criteria used in initiating the program.
Quality of food composition data
This topic has been the subject of a review (Greenfield & Southgate, 1985) in which it is suggested that close attention to the following will improve the quality of compositional data: the procedure for obtaining and handling the food sample; the choice and execution of the analytical method; and the record-keeping process.
Quality of a food composition database
Clearly, the quality of the food composition data will determine the quality of the entire system. In addition, the process of compilation is the filter which ensures that, ideally, only good quality data reach the user level of the data system.
Type of values
Currently the types of values appearing in food composition data systems fall into four main groups.
1. Original analytical values
These are values taken from the published literature or from unpublished laboratory reports and include original calculated values, e.g. protein values derived by multiplying the nitrogen content (by analysis) by the required factor.
2. Imputed values
These values are estimated. They may be derived from analytical values obtained for a similar food (e.g. values for peas used for beans) or for another form of the same food (e.g. values for boiled used for steamed). They may also be values derived by calculation from incomplete or partial analyses of a food (e.g. any value derived ‘by difference’).
3. Calculated values
These are values derived from recipes by calculation from the nutrient contents of the ingredients and corrected for preparation factors (weight loss or gain or preparation; nutrient losses or gains during preparation).
4. Borrowed values
These are values taken from other tables or databases without reference back to the original source. It should be noted that these may be processed data and that currently few tables or databases are referenced adequately so that it is difficult to trace the source of the data.
It is expected that attempts to improve the quality of food composition databases will involve the gradual maximisation of use of original analytical data, refinement of other types of data (better calculations, more legitimate imputations) and elimination of borrowed values.
Criteria for an ideal food composition database
The compilation process will have the objectives of meeting the criteria which have been set up for the user database. These will vary from one to another but may contain elements of our proposed criteria for an ideal user database which are:
The data management process
To implement the compilation process correctly it is important to distinguish the different levels of data management which are listed in Table 2. The evaluation of data is an iterative process between these various levels with the compiler reviewing successively all the procedures used in the generation of the compositional values. Frequently questions will be raised at a higher level in the system (data bank or user database levels) which require re-evaluation of the data at the archival or data source level. It is thus essential that the evaluative process is fully documented throughout.
Table 2. Levels of food composition data management.
| Level | Description | Format |
| Data source | Public and private technical literature containing analytical data, including published and unpublished papers or laboratory reports | As presented by original authors |
| Archival | Original data transposed to data files without amalgamation or modification. Scrutinised for consistency | One data set per original source to include details of origin and number of samples, sample handling, edible portion, waste, analytical methods and quality control used |
| Data bank | Data from all records for one food brought together to form the total pool of data | Common format |
| User database | Data selected; or combined to give mean values with estimates of variance for each food item | Common format |
Table 3. Suggested criteria for acceptance of food composition values*
| Criterion | Increasing acceptibility | Unacceptable # | ||
| 3 | 2 | 1 | 0 | |
| Identity of food | Unambiguous | Unambiguous | Unambiguous | Any ambiguity |
| Representativity§ of sample | Indigenous, representative | Indigenous, but not representative | Foreign | Not stated |
| Nature of material analysed | Clearly defined | Clearly defined | Clearly defined | Not clear/not stated |
| Sample preparation | Described and known to be thorough and conservative | Described and known to be thorough and conservative | Described and known to be thorough and conservative | Not stated or known to be destructive or contaminating |
| Analytical method | Established, validated by collaborative trial | Established and accepted/ established, modified, modification described and seems adequate/new, but fully described and internally validated | New, fully described and seems adequate but not internally validated/ Established, modified but modification not described or described and inadequate | Discredited/new but not fully described or internally validated/not stated |
| Number of units analysed | 10 | 3 | 1–2 | N/A |
| Quality control | Analytical duplicates and recoveries of standards and recoveries from a matrix or SRM | Analytical duplicates and recoveries of standards | Analytical duplicates | Nil/not stated |
| Mode of expression | Units/factors clearly stated | Units/factors clearly stated | Units/factors clearly stated | Units/factors not given |
* application of criteria may very from nutrient to nutrient and may be less vigorous where data are hard to obtain
# any value rating O on any criterion should not be accepted into the databank
§ representative of food as consumed by the population
Evaluation of compositional data
An approach to the formalization of criteria for evaluating data and levels of acceptability for each criterion is shown in Table 3; the choice and application of criteria will, in actuality, be determined by those responsible for individual data systems. However, the need for considerable information at data source level is highlighted. The availability of this information is the responsibility of the analysis and may increase with closer collaboration between analysis and users and compilers of compositional data.
Entry of data into the data system
It is suggested that the entry of compositional values into the data system at the archival level be in a printed or magnetic format similar to that shown in Table 4. An archival file is required for each data source for each food, and should be fully annotated and documented to save frequent reference to the data source. Values are usually recorded in the same mode of expression as used in the data source.
Databank level
Scrutiny and evaluation at the archival data file level will permit values to be transferred to the databank which comprises the complete pool of data available on a food, from all the different sources. The values held at databank level will have been transformed to common modes of expression and will represent the different forms of the nutrient or component on an individual basis where these are available (individual vitamins, dietary fibre components etc).
Table 4. Suggested format for an archival data file.
| Food name: | |||
Synonyms | |||
Systematic name | |||
| Reference to data source | |||
| Sampling protocol | |||
| Sample description | |||
| No. of units analysed | |||
| Constituent | Value | Method | Quality assurance |
| Edible portion | |||
| Water | |||
| Total nitrogen | |||
| Protein (N × factor) | |||
| Fat | |||
| etc | |||
All of the information, ideally, will be coded and annotated to provide the basis for evaluation of the data at this level. Scrutiny of the data in the databank may bring to light discordant analytical values. In principle, all values should be included in the amalgamation of data to provide user database levels, but occasionally discordant values may be rejected because scrutiny indicates valid reasons for rejection such as a discredited method of analysis or inappropriate sampling handling procedures. The databank is represented schematically in Table 5.
The user database
Schematically, the derivation of the user database values appears at the base of Table 5. These values may be selected values (particularly where the pool of data is small) or averaged or weighted values where such amalgamations of data are considered valid. The user database may include summated or derived values for components such as total sugars, total dietary fibre and vitamin A activity where this format has been determined as appropriate.
Table 5. Suggested format for databank for proximate composition*.
| Food name | Food descriptors | Proximate composition | |||||||||
| Source† | Edible portion | Water | Nitrogen | Protein | Fat | Available carbo hydrate | Total dietary fibre | Ash | Energy | Notes‡ | |
| Selected or averaged values | database values | ||||||||||
| Measure of dispersion | |||||||||||
| Logic of selection or calculation | |||||||||||
* similar banks will be needed for other nutrient groups
† sources may be named or coded
‡ to include comments on quality of values, reasons for inclusion, signature, date etc
Table 6. Confidence code for iron values in food.
| Confidence code | Meaning |
| A | The user can have confidence in the value |
| B | The user can have some confidence in the mean value; however, some questions have been raised about the value or the way it was obtained |
| C | There have been some serious questions raised about this value. It should be considered only as a best estimate of the level of this nutrient in this food. |
| From Exler (1982) | |
Indices of data quality
Exler (1982) has used a quality code to indicate the reliability of values appearing in a table of iron levels in foods (Table 6) based on the types of criteria used in Table 3. This concept could be adapted for use in other data systems, as a means of indicating the quality of values to the user.
Table 7. Summary of the compilation process.
| Level | Summary of operations | Type of scrutiny applied | Format |
| Data source | Collection of sources containing compositional data on foods. | Analagous to review or refereeing of scientific paper. Check on consistency of data. Preliminary assessment of data quality. | In form published. |
| Archival file | Compilation of information into separate file for each food and each data source. | Scrutiny of data source against formal criteria. Tentative assignment of some measure of data quality. | In data system format. Recording details of sampling and analytical procedures. |
| Data bank | Compilation of information into file for each food item. | Comparison of values from different sources. Statistical calculations to identify discordant data. Rescrutiny of archival or data source. Calculation of statistical measures. Confirmation of data quality. | In data system format. Food item and array of nutrient values. Record of statistical measures and data quality. |
| Data base | Compilation of information for each food item in data base. Calculation of derived values. | Combination of values to give mean. median (or selected) value for each nutrient. Scrutiny of values for internal consistency. Rescrutiny of data bank, archival file and data source. | In format required by user. |
Conclusion
Quality of food composition data and data systems has been discussed as an issue which is fundamental to the planning and organization of a data system program. Particular attention is drawn to quality assurance of analytical data and the appropriate evaluation of data in the compilation process (Table 7). However, in the final analysis it is the quality of usage of a food composition database which is important. This should be based on an understanding of the way in which data systems are constructed and thus on the uses and limitations of the systems themselves.
References
Exler, J. (1982): Home Economics Research Report No. 45. Washington, D.C.: U.S. Department of Agriculture.
Greenfield, H. & Southgate, D.A.T. (1985): A pragmatic approach to the production of good quality food composition data. ASEAN Food J. 1, 47.
Rand, W.M. & Young, V.R. (1983): International Network of Food Data Systems (INFOODS): report of a small international planning conference. Fd Nutr. Bull. 5, 15.
Southgate, D.A.T. (1974): Guidelines for the preparation of tables of food composition. Basel: S. Karger.
![]()
![]()