![]()
![]()
![]()
A.S. TRUSWELL
Human Nutrition Unit, University of Sydney, N.S.W. 2006, Australia.
‘If a nomenclature is not correct, the thinking will not be logical. If the thinking is not logical, then work can not be successful.’ — Confucius
Introduction
To prepare a terminology for international exchange it is essential to find out how compilers of food tables and users see their own terminology in many different countries and to listen to their reactions to any proposed system. There have been opportunities for listening to many different views at the Infoods meeting in Madrid in July 1984, in Heidelberg in May 1985, at the Brighton workshop in August 1985 and now at this Eurofoods meeting in Norwich (September, 1985). In between, Drs Rand and Klensin visited Sydney in September 1984 for discussions with me. Dr Rand established regular telephone conversations between Sydney and Cambridge, Mass. and in February 1985 we had a three day meeting at MIT with Will Rand, John Klensin, Ritva Butrum (NCI), Jean Pennington (FDA), Jean Stewart (USDA), Vernon Young, Nevin Scrimshaw and myself. We have had discussions with Dr Terry Leche, Secretary of INFIC (the International Feed Information Centre) and with Eurofoods as its coding system has developed.
Since January 1985 I have had a graduate research assistant, Kathryn Madafiglio, working with me in Sydney on Infoods terminology. I will look at six of our activities this year (1985).
1. Classification of Foods in Food Tables
When we reviewed the classification of foods in over 30 food tables from around the world we found three types of structures. Some food tables have clearly followed other earlier ones in their design. In general, food tables are evolving with time. There are good points and weak points in each. We found some excellent features in a few of the Third World tables which should be used more generally.
2. Infoods terminology
We have prepared a paper on the philosophy of Infoods terminology based on a meeting at MIT February 1985. The Infoods nomenclature and terminology system is being designed primarily to help communication between producers of analytical data and compilers of nutrient databases or national food tables. It does not have to be user-friendly for applied nutritionists in the field though ultimately it should improve the data available for them. It does not supersede or replace coding systems used in regional, national or specialized collections of food composition data.
Each time we eat a food or take a sample of it for chemical analysis or describe it, it is likely to be different in ways that can affect its composition in one way or another. This is a major premise of the Infoods terminology system. It is often assumed that we can find the perfect or typical form of each food. If we grow, process and cook a food properly and take enough samples and have them analysed by experienced chemists with the most accurate methods we can reach one best number for its content of different chemical components. This platonic, idealistic or dogmatic concept does not fit with modern biological science.
We take the empirical view. It is never possible to be sure that one sample of food is the same as another. This makes a code number or registration number misleading. Such a number implies an identity which does not exist. A registration number for a car means one car, the same shaped collection of metal and plastic. Any change to its structure is likely to be small. Another car could never have the same number unless there has been a legal or illegal transfer. An ISBN number for a book covers thousands of copies but they are produced by the printer in such a way that they should be indistinguishable. If he and his machines do their work properly each of the many thousands of words are in the same place on the same page in the same typeface.
Perhaps the nearest analogy to use of code numbers for present food tables is the numbers of the International classification of diseases (ICD). There is one number for (say) diabetes mellitus but all doctors know that the symptoms differ between patients with time and that there is a large range of possible values for the blood glucose. The ICD number is not used to predict the blood glucose value or the number and severity of symptoms; it is used for disease statistics, which for foods correspond to commodity consumption figures.
By using several words to describe a food sample we can improve the probability of predicting its chemical composition. The vitamin C content is affected by cultivar and by cooking so if we include these in the name or description of a food we are more likely to predict its vitamin C using food tables. Iodine content varies with the place where a food is grown so that if this is supplied with the name we can improve the chance of predicting iodine content.
Words are more suitable for our purposes of describing foods than numbers.
An international code number system for foods would also require an expensive registry. Delays in registration and allocation of numbers would be inevitable. Some scientists and some countries would not know about or not agree to or be too busy to communicate with the registry.
Hierarchial systems for classifying foods are not suitable for international exchange because:
Food composition data are being used today in many more ways than they were when the first food tables were compliled, originally to use in therapeutic dietetics. The decision to build a hierarchy for classifying objects is a decision about what is and is not important for ever. For international interchange none of the existing hierarchical systems for classifying foods are sufficiently flexible. This decision does not mean that hierarchical classification may not be very useful in national and even regional food tables.
The most practical approach is a multi-faceted naming system. The facets are independent. As in a diamond or a mountain there are different ways of looking at the object. There are several possible descriptors for each facet. The name thus is a series of descriptors, e.g..
These four foods so briefly named require some six facets:- ORIGIN (calves, lamb, beans, apples), PART (liver), COUNTRY OF ORIGIN (New Zealand), MANUFACTURER (Heinz), ADDITIVE (sugar), CULTIVAR (cooking apples).
The International Feed Information Centre (INFIC) uses six facets:- ORIGIN (scientific name), PART, PROCESS, STAGE OF MATURITY, CUTTING and GRADE, For human foods three of the INFIC facets are of major importance (origin, part, process), two of minor importance (maturity and grade) and one not needed (cutting). Additional facets are clearly needed for human foods, such as a distinction between factory ‘processing’ and kitchen ‘preparation’; manufacturer and brand name; container or wrapping; country where eaten and country of origin; list of ingredients.
Infoods has therefore adopted the principle of the INFIC system, as proposed originally by Ritva Butrum, but with more facets and some different descriptors.
3. Food groups
We collected details of food groups used in over 30 different food tables and systems.
4. Proposed food groups for Infoods
We produced for Infoods a new set of proposed food groups (n=44) which incorporates all the groups we had collected and eliminates the need for a miscellaneous group.
5. Nutrients and other components
Dr Southgate and I have thought of agreeing names of nutrients and other components as a much easier task than producing an agreed system for naming foods or agreed methods for analysing foods. There are already some international agreements about names of several classes of nutrients, e.g. amino acids, nutrient elements, and IUNS Committee 1/I has some rules for names of vitamins. Names of carbohydrates and fibre are in a more confusing state because of the different analytical methods being developed. Dr Southgate and I will meet the Infoods Executive during this meeting and a first draft of proposed Infoods names for nutrients will be circulated before the end of 1985.
6. Names of foods
We wrote a first draft of an Infoods guide for naming foods (April 1985). It was in the form of a questionnaire with a first set of 12 questions about names and country and use for the food. Before question 13 there was a branching, with different questions for single foods (scientific name, part, maturity) and for mixed foods (ingredients, recipe, reference). After four to six of these questions there followed seven common questions about processing, additives, cooking, and packaging. There were 23–25 questions in all. This guide was circulated before and very thoroughly discussed at the Infoods Terminology meeting in Heidelberg (19–23 May, 1985).
There were four sorts of comments and suggestions. (i) There were suggestions for additional information that would be interesting like a photograph or drawing, and a recipe file, etc. (ii) On the other hand some experienced participants warned that the guide might be too long (though six specimen descriptions were much shorter than the questionnaire. With abbreviations for different sorts of negative answers each took eight or nine lines of type). (iii) Questions about which languages could be used — e.g., any UN language or FAO language. (iv) Our proposed long set of food groups was not adopted.
To try and incorporate the suggestions at the Heidelberg meeting both for additional information and for a shorter list of facets the Infoods guide for naming and describing foods (July 1985) was written in time for presentation to the workshop at the International Nutrition Congress in Brighton and at this Eurofoods meeting in Norwich. In this there are optional and essential sections, like an income tax form. Everyone fills in some parts but whether you complete others depends on how you earn your money.
In this new guide the branching for additional descriptions of the food was into one of three possible types of food — single foods (no additions), mixed dishes (prepared in a kitchen of some sort) and manufactured multi-ingredient foods. In addition a last section was drafted about sampling (the bridge between the names of the food and the analytical data) for discussion with Dr David Southgate.
Thus the Infoods guide for naming and describing foods (July 1985) was made up in sections as follows:-
As well as feedback from presentations at Brighton and Norwich we received some detailed postal comments from members of our Committee. The system for naming foods has been further modified and steamlined. We have gone back to two branches — single foods and mixed foods. Though the border between these is difficult to define the concepts of single versus mixed are less confusing and less computer space will be needed. Written in brief form (without instructions and explanations) Infoods Nomenclature (October 1985) is given in the Appendix.
Appendix
Infoods Nomenclature (October 1985)
[FF = Fixed Format, CV = Controlled Vocabulary, FT = Free Text]
SECTION A: Source of information (UN language)
SECTION B: Literature reference (may be multiple — first should be most important)
SECTION C: Identification of food
SECTION D: Additional Information on Food Branch to complete either D. 1. or D.2.
D.1.: Single food or major ingredient
D.2.: Mixed dish, several major ingredients
SECTION E: User Information
SECTION F: Data Gathering
SECTION G: Additional Information
B. MEYER, H. J.C. VAN OOSTEN-VAN DER GOES, W. A. VAN STAVEREN and C. E. WEST
Department of Human Nutrition, Agricultural University, De Dreijen 12, 6703 BC Wageningen, The Netherlands.
Introduction
The usefulness of any food composition table or nutrient data base depends on the quality of the data used to construct it (Southgate, 1983). In general, original analytical data provides information of the highest quality. However in most countries, it is not feasible to construct a food composition table with only such data. Priorities for analytical work have to be drawn up and usually most effort is directed towards analysing foods which make a major contribution to the national diet. For specific individuals or groups, other foods may be of greater importance. Therefore it is necessary to estimate the nutrient content of foods rather than to have no data, which is usually represented by zero, in order to convert food intake to nutrient intake. As a result of the initial Eurofoods workshop held in Wageningen. The Netherlands in 1983 (West, 1985), a proposal for a project to collect data related to missing values in food composition tables was formulated. The main purposes of the project are as follows: (a) to determine which values are missing in food composition tables in the different countries of Europe and to obtain information on how the problem of missing values is being handled at the present time; (b) to analyse the information obtained and to bring about the exchange of data to enable missing values in tables to be filled; (c) to make suggestions on priorities for analysis of nutrients in those foods for which no data are available; and (d) to establish international guidelines for the estimation of missing values where no data are available.
In this report, preliminary results of a survey on missing values in 50 foods commonly consumed in Europe are presented.
Data collection
Participants
In 20 countries in Europe, the institutes responsible for compiling food composition tables were asked to participate. Replies were received from 13 countries, but it was not possible to evaluate the data from four of them. Thus the results of this survey concern food composition tables and nutrient data bases in nine countries (see Appendix 1).
Information requested
The study was based on a list of 50 ‘basic’ foods compiled by Mrs Lena Bergström (see Appendix 2). Information based on a further 50 foods commonly consumed in each country was also collected but the results of the analyses of these data will be presented in a subsequent paper.
Classification of nutrient values
Information on the type of values for energy and those nutrients most commonly included in current food composition tables (Appendix 3) were compiled by L. Arab (1985) together with the actual values. These were four categories, adapted from the proposal by Greenfield and Southgate (1985) as follows:
Original analytical values (type A): These values are taken from published literature or unpublished laboratory reports. This category includes original calculated values such as protein values derived by multiplying the nitrogen content by the required factor and “logical” values such as the content of cholesterol in vegetable products which can be assumed to be zero.
Imputed values (type B): These values are estimates derived from analytical values obtained for a similar food or another form of the same food. This category includes those derived by difference such as moisture and in some cases carbohydrate and values for chloride calculated from the sodium content.
Calculated values (type C): These values are those derived from recipes by calculation from the nutrient content of the ingredients corrected by the application of preparation factors. Such factors take into account losses or gains in weight of specific nutrients during preparation of the food.
Borrowed values (type D): These values are those derived from other tables or data bases without referring to the original source.
In classifying the data, four categories for values have been added. These categories are the following:
Absent values (type E): This category refers to the situation where there are no data available for inclusion in the table. Usually, these values are indicated by a blank, a dash or a question mark.
Values not included (type F): This category refers to the situation where the nutrient is not included in the table.
Unknown values (type G): The source of the value is unknown.
Mixed values (type H): This category has been introduced to describe values derived not only from other tables (borrowed values) but also from a limited number of original analytical data.
Data collection:
Participants in the survey were asked to supply information either by filling in the questionnaire provided or by overscoring a computer printout of their food consumption table with one of four fluorescent marker pens sent with the questionnaire. In addition to the classification of the data and the nutrient values themselves, the following information was also sought: a complete description of the table from which the data were derived; the local names of the foods and the scientific names of the foods.
Results
The results of this survey show that not all the foods regarded as ‘basic’ were included in the various European food composition tables. The number of foods included varied from 34 in the Italian table to 50 in the Swedish table from which the list of foods was taken (Table 1). This result stresses the differences in food patterns in the various countries of Europe.
Table 1. Proportion of original values for energy and specific nutrients for 50 basic foods in nine European food composition tables
| Proportion of data obtained from original analyses (referred to as type A data), % | |||||||
| Country | Number of foods listed | Energy | Total carbohydrates | Magnesium | Iron | Retinol | Thiamin |
| Fed. Rep. of Germany | 44 | 18 | 27 | 14 | 9 | 61 | 9 |
| Finland | 42 | 91 | 93 | 91 | 91 | 932 | 91 |
| Italy | 34 | 88 | 50 | 01 | 74 | 792 | 82 |
| The Netherlands | 45 | 22 | 36 | 01 | 24 | 222 | 27 |
| Norway | 47 | 30 | 36 | 01 | 45 | 452 | 51 |
| Poland | 36 | 6 | 0 | 42 | 42 | 61 | 42 |
| Portugal | 36 | 100 | 100 | 64 | 97 | 100 | 97 |
| Sweden | 50 | 32 | 30 | 14 | 42 | 84 | 34 |
| United Kingdom | 48 | 88 | 88 | 90 | 92 | 88 | 83 |
1) Not included in food composition table.
2) Expressed as retinol equivalents.
The frequencies of original analytical values varies not only between the tables but also for energy and important nutrients such as carbohydrate, magnesium, iron, retinol and thiamin (Table 1).
Portugal, Finland, Italy and the United Kingdom have a high proportion of original analytical values, while the tables from The Netherlands and the Federal Republic of Germany have only about 20 per cent of such values for energy and most nutrients.
Table 2. Proportion of missing values for energy and nutrients for 50 basic foods in nine European food composition tables
| Frequency of the absence of data (referred to as type E data), % | |||||||
| Country | Number of foods listed | Energy | Total carbohydrates | Magnesium | Iron | Retinol | Thiamin |
| Fed. Rep. of Germany | 44 | 0 | 7 | 18 | 11 | 16 | 11 |
| Finland | 42 | 0 | 0 | 01 | 0 | 02 | 0 |
| Italy | 34 | 0 | 12 | 01 | 12 | 62 | 3 |
| The Netherlands | 45 | 0 | 0 | 01 | 0 | 02 | 0 |
| Norway | 47 | 0 | 0 | 0 | 4 | 22 | 4 |
| Poland | 36 | 3 | 14 | 6 | 8 | 14 | 8 |
| Portugal | 36 | 0 | 0 | 36 | 3 | 0 | 3 |
| Sweden | 50 | 0 | 2 | 0 | 4 | 2 | 4 |
| United Kingdom | 48 | 0 | 0 | 0 | 0 | 6 | 6 |
1) Not included in food composition table.
2) Expressed as retinol equivalents.
Magnesium is not included in three tables and for the remaining tables, not many data are original analytical values. In general, for vitamins and minerals there are less original analytical values available than for energy, fat, protein and carbohydrate.
The proportion of missing values in the various tables for energy and specific nutrients for the basic foods (Table 2) indicates that different countries adopt quite different policies in constructing tables. For example, the aim in Portugal would seem to be to include only original analytical values and no calculated, imputed or borrowed data. On the other hand, Finland, the United Kingdom and The Netherlands have tables with few missing values. In the tables from Finland and the United Kingdom, the data are from original analyses while for The Netherlands, the data are derived from other sources (see Table 1).
Table 3. The origin of the energy values for 50 basic foods in nine European food composition tables
| Proportion of data from various sources, % | |||||||
| Country | Number of foods listed | Original | Imputed analytical value | Borrowed calculated value | Absent value | Source not known | Mixed value |
| Fed. Rep. of Germany | 44 | 18 | 2 | 9 | 0 | 0 | 71 |
| Finland | 42 | 91 | 2 | 7 | 0 | 0 | 0 |
| Italy | 34 | 88 | 0 | 12 | 0 | 0 | 0 |
| The Netherlands | 45 | 22 | 2 | 11 | 0 | 2 | 62 |
| Norway | 47 | 30 | 17 | 2 | 0 | 0 | 51 |
| Poland | 36 | 6 | 19 | 39 | 3 | 0 | 33 |
| Portugal | 36 | 100 | 0 | 0 | 0 | 0 | 0 |
| Sweden | 50 | 32 | 0 | 50 | 0 | 0 | 18 |
| United Kingdom | 48 | 88 | 8 | 0 | 0 | 0 | 4 |
The origin of the energy values for the basic foods is given in Table 3. Imputed and calculated values are grouped together because, from the information supplied, it was often difficult to distinguish between the two. The values for energy are calculated by applying the Atwater factors to the content of protein, fat and carbohydate. If the values for these proximate constituents in one food were of more than one type, the energy value for such a food was classified as “mixed”. As can be seen from Table 3, the German, Dutch and Norwegian food composition tables have many values of mixed origin. This can be attributed to the fact that in these tables, carbohydrates are often estimated by difference as follows:
Carbohydrate, g = 100g — weight in g of fat, protein, ash and water.
As can be seen in Table 3, many food composition tables have a relatively large proportion of borrowed values. When the original source of such data is not given, as is usually the case, it is not possible to evaluate the quality of such data. Sometimes, the values are based on high quality analyses, but the values can just as well be rough estimates. When constructing tables, it is very important to state the source of the data. The problem becomes more acute when tables go through a series of revisions because often it is just said that a value has been taken over from a previous edition of the table and the true origin of the value becomes lost.
Conclusion
The results of this study give a general impression of the quality of data in the various European food composition tables examined. It is only an impression because the 50 ‘basic’ foods did not appear in all of the tables. The data quality, as expressed by the proportion of original analytical data, varied between the tables and also within the tables with respect to different nutrients.
When the results of the second part of the study, involving 50 of the most important foods in each country apart from the 50 ‘basic’ foods mentioned above, become available this will provide further information on the quality of data in the various tables.
References
Arab, L. (1985): Summary of survey of food composition tables and nutrient data banks in Europe. Ann, Nutr, Metab, 29, Suppl. 1, 39.
Greenfield, H. and Southgate, D.A.T. (1985): A pragmatic approach to the production of good quality food composition data. Asean Food J. 1, 47.
Southgate, D.A.T. (1983): Availability of and needs for reliable analytical methods for the assay of foods. Food and Nutr. Bull, 5, 30.
West, C.E. (ed) (1985): Eurofoods: Towards compatability of nutrient data banks in Europe. Ann. Nutr, Metab. 29, Suppl. 1, 72pp.
APPENDIX I
List of food composition tables and nutrient data bases studied (Contact persons are given in parenthesis).
APPENDIX 2
List of 50 ‘basic’ foods examined
APPENDIX 3
Energy and nutrients included in the evaluation
- Energy
- Protein
- Total fat
- Total sfa (saturated fatty acids)
- Total ufa (unsaturated fatty acids)
- Total pufa (polyunsaturated fatty acids)
- Linoleic acid
- Cholesterol
- Total CHO (carbohydrates)
- Starch
- Dietary fibre
- Total sugars (= mono- and disaccharides)
- Alcohol
- Sodium
- Potassium
- Calcium
- Magnesium
- Phosphorus
- Iron
- Zinc
- Iodine
- Retinol
- β-carotene
- Vitamin E
- Thiamin
- Riboflavin
- Nicotinic acid (Niacin)
- Vitamin B6 total
- Ascorbic acid
M. B. KATAN and P. C. HOLLMAN
Department of Human Nutrition, De Dreijen 12, 6703 BC Wageningen, The Netherlands.
The Eurofoods interlaboratory trial 1985 was set up to determine whether differences in laboratory procedures between countries form an important cause of discrepancies between nutrient values in different food tables and nutrient data banks. Twenty leading laboratories in Europe and the U.S.A. participated in the trial. Each received a well-homogenized dry sample of 100 g of egg powder, full-fat milk powder, whole rye meal, whole wheat meal, biscuits and French beans. Heterogeneity between samples of the same food was checked by analysis of nitrogen in 10 random samples of each food, and was found to be negligible (coefficient of variation 0.1–0.2%). Each laboratory was requested to perform analyses of dry weight by a prescribed vacuum stove method, and of protein, fat, available carbohydrates, total dietary fibre and ash by its own routine method. Analyses were made in duplicate, with two technicians each contributing one value. All results were later recalculated to dry weight to eliminate the effect of losses or gains in moisture.
- For dry weight, the coefficient of variation between laboratories (CV between) ranged from 0.3–0.6%. Optional non-vacuum methods yielded results quite similar to those of the prescribed method.
- For protection the CV between ranged from 2.8% for egg to 6.4% for wheat and rye. Recalculation using uniform Kjeldahl factors reduced these CV's to 2.7, 4.7 and 5.2% respectively. Reproductibility within laboratories was occasionally poor.
- The CV between for total fat ranged from 5.4% for milk to 54.0% for french beans, the CV being higher when the absolute fat content of the food was lower. The reported fat content of egg powder ranged from 29 to 44 g/100 g dry weight. Part of the variability was clearly due to different laboratories using different methods for the same food, for instance acid hydrolyses versus solvent extraction. However, laboratories using ostensibly similar methods still reported widely diverging results.
- For available carbohydrates the CV between (excluding egg) ranged from 9% for biscuits to 27% for beans. Individual results for carbohydrate content of whole wheat meal ranged from 36 to 82 g/100 g dry weigh. Variability was somewhat reduced if differences in mode of expression (as g of polymeric starch versus as g of equivalent monosaccharides) were eliminated; the CV between now ranged from 7 to 23%. Effects of specific methods could not be identified because too many different methods were used.
- The CV between for total dietary fibre ranged from 23% for french beans to 84% for biscuits. A major part of this variability was due to the use of methods of different principle.
- Results for ash were reasonably consistent, with a CV between ranging from 3.3% for milk to 6.7% for egg.
- It is concluded that leading laboratories in different countries may produce Widely different values for proximate constituents (macronutrients) in common foods. There is a need for better standardization of methods. As an initial step, reference materials of certified nutrient concentration should be produced and be made widely available.
L. ARAB
University of Heidelberg, Bergheiman Str. 58, 6900 Heidelberg, Federal Republic of Germany.
Introduction
Few people have known how many and which compositional information on foods is available in Europe. Yet the thirst for information on foods increases as diet becomes implicated in greater and greater roles in cancer, heart disease and the instigation and promotion of other chronic diseases which account for the majority of premature mortality in Europe.
To enhance the availability of information, facilitate its use and promote a responsible application, a study is being conducted on merging nutrient (and non-nutrient) databases. This is a progress report of the advances and obstacles noted within the first year.
Merging databases — the technical issues
Simple entry onto a single host computer of data from various countries, once permission was received, presented some problems. Receiving permission also presented problems (see legal issues).
The first problem was recognized as lists were received from groups unable to prepare magnetic tapes. Some of the characters on these lists were not available on the keyboards used. Some were incompatible with specific printers. Others were just as technically difficult to enter as Chinese might be, because the sequence of consonants was so unfamiliar.
Floppy discs were also sent upon occasion with the hope that they might be readable. We discovered however that due to the formatting, density and operating system, floppy files created on a Macro-Micro could not be interpreted by our Apples, Commodores, Siemens or IBM PCs. We returned to entering the original lists manually.
Data tapes were thought to be the most desirable from for an exchange — relatively standardized and providing previously entered, edited information and text. This was often not as simple as hoped. The tapes labelled with more than eight characters from the United Kingdom could not be read by our IBM. Two other sets of data tapes became unreadable (also to their producer) during their transit, Unusual systems for marking beginnings and ends, unstandardized units of measure for a single nutrient within a data tape and lack of documentation made easy and efficient reading difficult. The ubiquitous poor documentation was a real hindrance. Neither position of parameters nor units were generally given. In one case the resignation of the only programmer caused problems for the group concerned and for us.
The most exciting and satisfying technical discovery was that EARN (the European Academic Research Network, 1985) could be used for transfer of large data files. After two trials at reading a Netherlands UCV tape (Kommissie, 1985), the work groups attempted to send the information directly — and the author upon logging in discovered instead of the normal remark that a message of 15 records was awaiting receipt and acknowledgement, a message stating that 30 000 records from a user from the Netherlands was found.
It was a complete, perfect file of Dutch and English names and nutrient values with source codes (we were ecstatic!).
Merging databases — the legal issues
Some countries offer their edited data as a free public service; other table producers are attempting to limit use (and access) by charging fees and even requesting licencing agreements from the user.
Concern was expressed about potential loss of revenues from local sales of tables if national food tables are available via an international merged online database. This, in certain countries, created a reluctance to voluntarily contribute data. Although by the Berne Convention (1886), scientific information is neither copyrightable nor patentable, at least one country is attempting to pass legislation to limit third party use. All the contributions of data for this merged database project were made available under the condition that this was only in the interest of a feasibility study, and was not to be distributed further.
Table 1. Vitamin Units.
| Vitamin A | Retinol | Retinol-equiv. | Carotene | total Carotinoids | active carotene provit. A | β-carotene | Vitamin D | Vitamin E | α-tocopherol | α-tocopherol equiv. | Vitamin K | |
| Austria | Foreign tables in use | |||||||||||
| Belgium | Er+ | |||||||||||
| Denmark | ug | ug | ug | ug | mg | mg | kl | |||||
| FRG | mg | mg | mg | ug | mg | |||||||
| Finl. Varo | ||||||||||||
Turp. | ug | |||||||||||
Koiv. | ||||||||||||
| France: Ostr. | mg | mg | mg | |||||||||
Randoin | mg | mg | mg | mg | ||||||||
Renaud | mg | mg | mg | mg | ||||||||
| GDR | mg | mg | mg | mg | ||||||||
| Greece | ||||||||||||
| Ireland | Foreign tables in use | |||||||||||
| Italy: Carn. | ug | |||||||||||
Fidanza | ug | ug | ug | |||||||||
| Norway | IU | |||||||||||
| Poland | ug | ug | ug | |||||||||
| Portugal | IU | ug | ||||||||||
| Spain | ug | ug | ||||||||||
| Sweden: | ||||||||||||
1. Skolupplage | mg | mg | mg | ug | mg | |||||||
2. Large tab. | mg/ | mg/kg | kg | mg/ | kg | ug/ | mg/kg | mg/kg | kg | |||
| The Netherl. | mg | |||||||||||
| UK | ug | ug | ug | mg | ||||||||
+1 ER = 1 ug Retinol = 6 ug β-Carotene
Merging databases — units, mode of expression and formats
Food tables (and databases) differ tremendously in their formats — some are books, others multiple volumes; some organized towards presentation of all nutrient information available for a single basic food, others are constructed around presenting the content of single nutrients for all source foods. The presentation formats are in some cases lists, in others matrices some with empty space for unmeasured values, others signalize missing values and some just drop any presentation of a mention of the nutrient in the case that no value is available, so that distinguishing between missing and zero is difficult.
In those tables which are organized in a tabular form, the sequence of components differ, as seen in diagram 1, and contributes to the possible errors in use. Also units of measure and expression differ — vitamin A μg in some, mmol in others, expression either as retinol equivalents, β-carotene or total carotenes. (The number of significant digits reported upon also range from two to four). An example of the presence of values and differences in expression for vitamins for European tables is shown in Table 1.
Diagram 1. Examples of different food table formats.
btbrs| TABLE | DIRECTION OF ENTRIES | COMPONENTS | |||||||
| FRC | ↓ | Energy | Waste | Water | Protein | Fat | Carbohydrates | Minerals total | . . . . |
| CDR | → | Code | Name | Energy | Water | Protein | Purin | Fat | . . . . |
| GREECE | → | Weight | Energy | Protein | Fat | Carbohydrates | Cholesterol | ||
| ITALY | → | Code | Edible part | Water | Protein | Fat | Carbohydrates | Energy | . . . . |
| NETHERLANDS | → | Energy | Protein | Plant Protein | Animal Protein | Fat | Saturated Fat | Monounsaturated Fat | . . . . |
| NORWAY | → | Edible Protein | Water | Energy | Protein | Fat | Carbohydrates | Minerals | . . . . |
| UNITED KINGDOM | → | Description | No. of samples | Water | Sugar | Starch Dextrose | Fibres | Total Nitrogen | . . . . |
Translational and terminology issues
Nothing new to persons professionally involved in translations, but a revelation to us was the finding that two similar terms have areas in which their meanings overlap, areas in which they are distinctly different (Iljon, 1977) and that agreement on development of a multilingual thesaurus is an expensive, painful process. It is not unlikely that the area of foods presented special problems because of common widespread use of the same terms (for different products) whole grain breads being an example. German and British whole grain breads are as different as night and day — whereas Norwegian whole grains are unleavened and sweet.
Scientific names can be applied to primary foods, but it has been reported that their misuse too is widespread and gross. Polacci reports non correspondence between local names, English and Latin names and both multiple Latin names for English names (W. Polacci: Review on ‘Standardized food terminology’ presented at the Eurofoods — Infoods Terminology meeting May 19–22, 1985, Heidelberg). An example drawn from the latter is ‘catfish’ which can be Bagrus bayad, Clarias lazera, Clupisoma garua, Eutropiichthys vacha, Heteropneustses fossilis, Mystus corsula, Mystus gulio, Mystus vittatus, Silonia silonia, Silurus triostegus, Syndontis spp., and Wallagu attu (different genus and families).
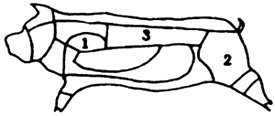
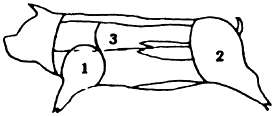
Even after clarification about the actual genus and species is achieved, agreement on the portion analysed (edible part) is needed. The different systems for cutting and labelling carcass sections presented problems due to considerable overlap (see Diagram 2).
Diagram 2. Pork meat charts.
| Poland | Austria | |
 | 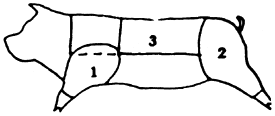 | |
| Federal Republic of Germany | ||
 | 1 shoulder | |
| 2 leg | ||
| 3 Join | ||
| Sweden | USA | |
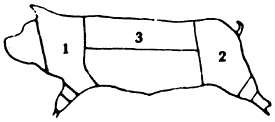 | 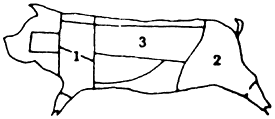 | |
During coding discussions, another issue of edible portion arose. The French delegate, in a workgroup with three Germans informed his colleagues of the unacceptability of eating Camembert cheese in its entirety — crust and all (as is generally done in the FRG). Thus the beliefs in edible portions differ, and the nutrient values which are based on the French food tables, do not include the outer portion (certainly rich in B vitamins) which is regularly consumed in other countries.
Processing and preparation methods are from terminology here, a difficult area. Particularly in this field, words have overlapping meanings in different cultures. The example of “braten” is a good one, a word which translated means without fat in one language and with fat in another.
In the course of this study a database was constructed including the native name and English translations (where possible) for all foods included in 15 published tables. To simplify cross referencing, Eurocode 2 numbers were assigned. The translations were in many cases newly made and provided for largely by Eurofood collaborators in the various countries. Entry of the native names was hindered by the need of special keyboards and character recognition for special non-English characters such as Ç, Å, Æ, t, ε, Ô. The tables from which translations exist can be seen in Table 2.
A collection of translations of food table introductory materials into English has also begun. Those currently available are also shown in Table 2.
Table 2. English translations from the introductions and foods in major European food tables.
Foods Introduction
| * | * | DENMARK | Moller |
| * | * | FED. REP. GERMANY | Souci/Fachmann/Kraut |
| * | FINLAND | Koivistoinen | |
| * | Turpeinen | ||
| * | * | Varo | |
| * | * | FRANCE | Ostrowski/Josse |
| * | Randoin et al. | ||
| * | * | Renaud et al. | |
| * | * | GERMAN DEN. REP. | Haenel |
| * | * | GREECE | Trichopoulou |
| * | * | ITALY | Carnovale/Miuccio |
| Fidanza/Versiglione | |||
| * | * | NORWAY | The National Nutrition Council |
| * | * | POLAND | Piekarska/Los-Kuczera |
| * | * | PORTUGAL | Gonsalves Ferreira/da Silva Graca |
| * | * | SPAIN | Arias/Moreiras-Varela/Extremera |
| * | * | SWEDEN | Statens Livsmedelsverk |
| * | THE NETHERLANDS | UCV-Kommissie | |
| * | * | UNITED KINGDOM | Paul/Southgate |
In the field of terminology and nutrient content mixed foods do present the greatest problem. It is absolutely essential to have some type of “recipe” or proportions of ingredients stored for any food codable which contains more than one primary foodstuff. Without recipes conversion to elemental foods for calculation of intakes (of eggs for example) can not be achieved. Recipes are also necessary for comparing foods. And they are desirable in any databases since they are often eaten, and the demand of a complete recipe process for each occasion of mixed food consumption is, in a large study, practically infeasible.
A complete database
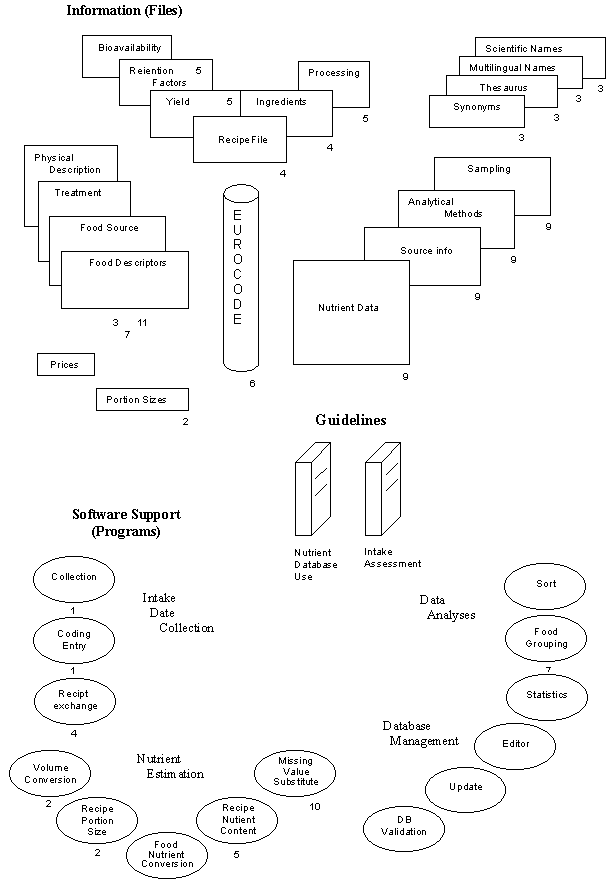
From these thoughts, the concept of a total database, as outlined in diagram 3 was developed, incorporating many useful or necessary datafiles for different users.
Diagram 3 organizes the information on foods needed for different tasks into the following four groups.
Diagram 3. Components of a complete food — nutrient database.
Nutrient and non-nutrient composition values of food
These details include analytical method, sampling, source and type of information about the origin of these values.
Language files
These files provide the ability to reference foods on their scientific names, native names, English (and potentially any number of other European languages) and their descriptors.
Recipe files
In addition to consumption levels of primary products, information is desired by various groups on foods as consumed. Because issues of bioavailability, effects of processing interest and in the reasons for selection of specific food products, it is no longer satisfactory to convert intake information into ‘raw ingredients’. Intake information should be stored as collected (and consumed), but potentially convertible into ingredients (e.g. when a pizza is consumed, it should be reducible to flour, oil, tomatoes, cheese intakes but stored in a single code), and for these files on standard, typical or averaged recipes for common mixed foods are needed. Recipe files are needed including proportion of each ingredient, processing and preparation steps involved for individual foods as well as yield and retention factors for food groups and individual nutrients.
Descriptors of foods
‘Descriptors’, including the characteristics and properties of foods and the preparation and preservation methods employed, are needed for identification of foods, their edible parts and to determine similarity of items.
All of these are components seen as structured around a common food code, to be used for cross referencing. Of course, files alone provide little information, they need to be accessed in a variety of ways, and a number of common applications are reflected in the list of software components which frame the bottom of diagram 3. They too are organized by function, intake data collection, compositional editing, updating, validation, calculation, and statistical analysis programmes. In a total system, guidelines and footnotes for use should be included.
The successful feasibility attempt in merging a few European food composition databases has shown that, despite all the interesting obstacles and surprises, a common system is feasible. Printouts from this system have graphically illustrated some of the uses which could be made of it (M. Wittler and L. Arab: Eurocode, 1985 — separate report in this monograph), and the project itself has stimulated new ideas and a design concept for a database on foods which would serve nutritionists, food technologists, epidemiologists, physicians, and dieticians.
The progress and promise of what this source could offer has led to a recommendation by an expert committee of the European Community Umbrella programme to begin supporting a similar venture. They advised that ‘Research in this area, and indeed the whole of the European food safety and wholesomeness evaluation would benefit greatly from being underpinned by a coordinated European Data Base capable of cataloguing all the individual food products on the market in Europe and the available data on their composition and method of manufacture and processing’.
Conclusion
A feasibility trial merger of European food composition tables revealed that the technical obstacles, however tedious, are not difficult. The major hindrances are language and terminology. Proposals for resolving these are made, within the framework of a multifaceted food-component database structure. They include proposals for a standardized food coding and descriptor system. Such a system would facilitate enhanced use of foreign data, and should be designed to protect against inappropriate use of data for nutrient values of foods or products from remote dissimilar sources. A danger which already exists and is worsened by the language barriers currently confronting most conscientious ‘foreign users’.
References
Earn (European Academic and Research Network) (1985): Pocket reference summary. 2nd edition
Iljon A. (1977): Development of a multilingual thesaurus for food and science and technology. Alimenta 16, 163–166.
UCV Table (1985): Kommissie UCV (cd.) The Hague: Voorlichtingsbureau voor de Voeding.
![]()
![]()
![]()