![]()
![]()
![]()
By Hélène Dessard
The intent of this annex is to review some of the underlying principles and definitions of sampling theory, enabling a better grasp of the basics of different sampling techniques. Users can then select a sampling design to meet their own objective, one relying more on statistical considerations than intuitive personal projections.
The objective of sampling is to discover the properties of a given population by analyzing a fraction of this population. The rationale is the impossibility of enumerating the characteristics of an entire population, due to constraints of time and money, not to mention the size of the population! The point is not usually to discover the value (s) of the characteristic (s) of all elements of a population, but rather to make statistical inferences (extrapolations or predictions) from a sample of these values, i.e., to infer the whole from a subset or sub-universe. Obviously, as only a fraction of the population is observed, the extrapolation inevitably contains an element of error. This is called the sampling error, and the hope is to minimise it by choosing the most suitable sampling plan to obtain the best possible extrapolation.
Finite population U: consists of all N units on which we measure one (or more than one3 ) characteristics Y = (Y1, Y2,... YN). We wish to discover specific characteristics of a finite population4 , noted as q also called parameters. This universe has as many dimensions as there are characteristics to estimate. If we want to know the total number of trees in a stand and their average height, then qis a vector of length 2.
Sample5 : This is a sub-set (or sub-universe), size n W N, of the population, on the basis of which specific characteristics of the population will be "estimated ». The way in which it is constituted also defines its properties, e.g. the multiple occurrence of a single unit (in the case of sampling with replacement), the order of the units, etc.
Estimator: this is simply a function of the data Φ (s), for example a weighted sum, for calculating a mean. The estimator is a random variable, and, as such, is also characterized by its probability distribution in the set of samples (which we call its sampling distribution). It thus possesses an expected value and a variance. One may have several estimators available for the estimation of a given parameter, so one practical criterion is to take the mean square error: which is the expected deviation between the estimator and the true value of the parameter, i.e. E [(Φ (s) - q )2 ]. Practically speaking, the smaller the latter, the more exact the estimate.
Sampling design6 : Statistically speaking, the sampling design, or plan, designates the law of probability defined for all possible sets or universes, i.e., the probability that a sample will be selected. For example, if the population is made up of three components { 1, 2, 3} , the set of non ordered samples with no replacement, and size 2, is
ζ = { { 1, 2} , { 1, 3} , { 2, 3} } .
For each samples of ζ, P(s) ≥ 0 is defined, where
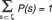
For example: P({ 1,2} ) = 0,6; P({ 2,3} ) = 0,3; P({ 1,3} ) = 0,1. What we have here is an unequal probabilities design.
Sampling strategy: combination of the selection of the sampling design and of the estimator.
Probability of inclusion: probability that a unit i will belong to the sample (simple probability πi) or two units i and j simultaneously (double or joint probability πij) (Cochran, 1977). These are calculated as follows:
Going back to the preceding example, we have
π1 = 0,7; π2 = 0,9; π3 = 0,4.
Variable of interest: variable measured on sample units for which we want to estimate a function, i.e., a total, mean, ratio, etc.
Dummy Variable7 : a variable correlated with the known variable of interest for all units of the population prior to the inventory.
Representativity: One of a sample is said to be "representative" when none of the probablilities of inclusion are nil. In other words, every unit has an equal chance of belonging to the sample. The probabilities are defined by the sampling plan. If we want to obtain an exact estimation, we will have to increase sampling intensity in the zones of greatest variability, with respect to the more homogeneous zones.
Overpopulation model: The conventional approach considers the items measured as fixed, so that the sampling procedure alone forms the basis of inference8 . The model approach considers the observed characteristics to be manifestations of random variables. The target population is itself a random sample of one (or more than one) superpopulation (s). The sample is thus the product of a dual sampling: the first samples the observed N values of the population, and the second consists of the sampling design, conditional upon these values. The inference made is thus also based on the model. This approach can prove extremely helpful in choosing a design.
Robustness: this very general concept signifies that a statistical procedure is described as robust if it is not very sensitive to departure from the assumptions on which it depends.
Prior, posterior data: although this notion was touched upon in the definition of a dummy variable, the dummy data will be accorded a more general scope. When prior data is incorporated, the sampling strategies are greater in number, and the user may have a better chance of choosing the right plan (though the assessment will be more costly!). When posterior data is used, it serves to "correct the estimators", such as the post-stratified estimator, but the data often remains under-utilised. In all cases, if one or more dummy variables are available, it is preferable to use prior data, where possible.
The best sampling design cannot be selected solely in terms of its theoretical properties, however. Sampling campaigns have their costs -- financial costs, plus the time and effort expended, which are not the same everywhere. These costs are limiting factors for, or constraints to, the correct execution of a sampling plan, especially as concerns sample size. Our final goal is to estimate given characteristics of the population to a pre-determined degree of exactitude. Attaining this for a given strategy depends on the degree of variability of this characteristic within the population. Obviously, high variability implies a larger size sample. The desired degree of exactitude will not be obtained at the same cost from all conceivable strategies. So in a situation where there are constraints, it is essential to evaluate strategies in terms of the ratio between exactitude and cost, called the efficiency ratio.
Even endeavouring to select the most seemingly pertinent sampling design, there will always be an element of chance. It is not simple to assess the inherent risks. Even breaking down the mean square error in terms of the different sampling design parametres, such as sampling rate, number of plot, area and shape of plots, and so forth, these parameters are not independant of one another. For example, as plot size increases, the coefficient of variation among the plots diminishes in accordance with a ratio like the following:
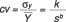
where cv is the coefficient of variation of Y, the standard deviation of Y,
is the mean of Yi, k and b of the positive coefficients, and S the plot surface area. Generally speaking, b < 0,5 and therefore, for the same area sampling rate, exactitude diminishes with plot size, whereas efficiency may be greater..
Ardilly (1994) explains that "even for such a simple parameter as a mean, there is no demonstrably optimum sampling design, i.e., some "miracle" combination of sampling method and estimation method which produces, whatever the values of Yi taken by the individual N of the population, a smaller mean square error than can be obtained with any other design". ».
We begin by pointing out the advantages and disadvantages of conventional designs, models, and go on to discuss new approaches deemed more suitable to assess a scarce and dispersed resource such as Trees outside forests.
Conventional designs. All sampling plans whose inference is based on the probability distribution defined for all samples are termed conventional designs. Excluded are so-called sequential designs where data is collected until such time as the properties of the estimator satisfy a given criterion. Such traditional designs have been broadly described by Cochran (1977) and in the forestry context by De Vries (1986) and FAO (1973). Their properties are well-known, and they are applicable for forest resource assessment "within the forest». Having said that, they may also be suitable for assessing trees outside forests provided these trees are neither too isolated or too dispersed. It is therefore advisable to have some idea of the dispersion and density of the target to be estimated. We shall simply state the basic principles of the major conventional designs, as well as a few elements for assessing their response.
Single stage probability designs:
Multistage probability designs:
The simple probability design is universal, requiring no previous data on the population, and all conventional statistical methods can be applied. On the other hand the estimators are less exact than in other designs .
The attraction of the systematic design, much used in the field of ecology, is its ease of implementation and regular overlap of a study area. It is better than the simple probability design when the population presents a positive autocorrelation or linear tendency, but can prove catastrophic where the periodicity of the variable coincides with the spacing of the grid.
The other other designs are based on the availability of a structural datum.
The unequal probabilities design is based on the probability that a given unit will be selected depending on the value of the associated dummy variable. Here we distinguish between the probability of selection and the probability of inclusion. Probability of selection is the chance that a unit will be drawn when the sample is constituted, and the probability of inclusion is the chance that a unit will be found in the sample once the sample has been formed. This design is recommended when the variable of interest is roughly proportionate to the dummy variable, the latter varies greatly from one unit to the next, and the unit cost of measurement is independant of the unit.
The stratified design is always appreciably more exact provided stratification is correctly done based on a criterion with the closest possible link to the variable of interest. But if the boundaries of the strata are ill-defined, exactitude will suffer greatly. To a certain point, the more strata, the more exact the results. Classification methods can be utilized to the determine the number of strata and their boundaries.
Cluster design is based on the same idea as stratified design, but their respective fields of application are: where intra-class variance is great and inter-class variance small, the cluster plan is used. In the opposite case, stratified design is used..
Lastly, multi-stage design is suitable for naturally hierarchical populations where the goal is to estimate the parameters of interest for different levels of the population..
Adaptive cluster sampling. This is a two-stage design. In the first, an initial sample of units is selected in accordance with a conventional design. Phase two is like cluster sampling, but the procedure is adaptive. The pursuit of the sample is a function of the value of the variable measured. The population is made up of the universe of units resulting from the partition9 of the study domain. First, a sub-set of units is selected by conventional design for a given sampling rate. Then, the characteristic y is measured for each unit u: if y meets a pre-defined condition, then all units in the vicinity of u are also measured. The process is continued until the variable y observed in each contiguous unit meets the pre-defined condition .
For example, we may imagine small woodlots scattered at low densities over a fairly large area, Obviously, the simple probability design is not very efficient in this situation. The parameter to estimate is the total number of trees in the region. The region is broken down into (square or rectangular) sub-units u on which the variable y, which is the number of units in u, is measured. The condition is the presence of at least one tree. The vicinity of a unit is made up of the eight contiguous cells. An initial sample is drawn by simple random sampling, then y is measured for each unit in the sample.
If y ≥ 1, then the eight contiguous units are observed, then the units contiguous to each of these eight are observed to check whether y ≥ 1, and if not, measurement is halted. Where the initial sample does not meet the condition, the contiguous units are not observed.
To sum up, all units belonging to the initial sample and all units measured (including neighboring cells where y = 0) are part of the final sample. What we have here, then, is a variable size cluster sampling design.
This technique is particularly sutiable for assessing a scarce resource, grouped into aggregates which are also dispersed within the study area. This type of inventory has rarely been applied, according to the literature, and thus few field assessments have been made. Thompson (1992), however, systematically compared conventional designs with their adaptive version, which involves the same type of design at phase one. According to these studies, ASC efficiency increases with the size of the sample and the extent to which the population is aggregated, compared to other designs.
Guided transect sampling. This is also a two-stage design requiring a dummy variable at stage two. This technique, proposed by Ståhl et al. (2000), has never been implemented in the field or compared (by simulation) with systematic continuous transect sampling. We present it here anyway as it might prove very promising in some cases.
The study domain is divided into transects of several adjoining strips divided into quadrats. Each quadrat is associated with a value of the dummy variable. A sample transect is constituted in accordance with a given design. The move from one quadrat to the next is then defined in accordance with a selection strategy depending on the dummy variable.
For example, a sample transect is constituted by simple probability sampling or by an unequal probabilities sampling proportionate to the sum of the dummy variable on the transect. The authors looked at three quadrat selection strategies at stage two:
The authors compare guided transect sampling (GTS) to the traditional transect continuous sampling (TCS), for an identical sampling rate and six types of forests classified in accordance with the abundance and dispersion of the resource. They conclude that GTS is more efficient than TCS for a dispersed population and that the greatest exactitude is obtained with strategy 2. They also note that more in-depth study is required before the method can be applied in the field!
Sampling by classed universes. This little -used method may be of interest where the variable of interest is too hard to observe and/or expensive to measure. The two-stage procedure is based on the existence of a concomitant variable. The first step is to constitute a simple probability sample of a size m x m which is randomly split into m samples of m size. The units of each sample are then ranked in increasing order based on the observation of the concomitant variable. This "observation" overlaps all inexpensive assessment methods, such as visual classification (e.g.,by size or colour) or expert opinion, etc.. At stage two, the variable of interest is measured on m units selected as follows: the unit of rank 1 in the first sample, the unit of rank 2 in the second and so on up to the m-th in the last sample. This second stage is repeated r times, based on r new random splits of m2 units. In all, mr measurements are effected. This method is one alternative to the random stratified inventory, much more efficient when stratification costs are high compared to classification costs and where there is a low correlation between the dummy variable and the variable of interest. It is also one of the few techniques which can bring in non-quantitative data (used as the basis for classification) such as expert opinions.
To cope with the emergence of the concept of auxiliary data plus the problem of defining an optimum sampling strategy, statisticians such as Basu (1971), Brewer (1963), and Royall (1971) suggested in the 1970s that the values of the variable of interest be structured. They simply considered that the values Yi were no longer fixed quantities, but true random variables. The population observed is thus simply a manifestation of the collection of random variables. The term superpopulation model is often used. There is an immediate mathematical advantage: all data contained by the N size parameter, that is, by (Y1, Y2,... Yn), can be wholly summed up in the simplest case by a number, so that the Yi variables are distributed identically and independently in accordance with Poisson's law defined by a single parameter λ). It can then be shown that with this new approach, optimum designs can be defined in certain families of sampling designs. The estimate of error is simplified by the reduced size of the parameter on which errors depend, and designs can be compared. A further consequence of this approach is that the choice of the estimator becomes completely independant of the sampling design. In other words, a sample can be constituted at will. Obviously, the method does entail certain risks inherent in fitting the model to the true distribution of the variable. If the model is very remote from the reality, inference may give very poor results, i.e., highly skewed or highly variable estimates.
Two main trends emerge from the literature: designs where inference is wholly dependant on the model, and model-based designs remaining robust with respect to the model (Särndal et al., 1992).
Often enough, it may be of interest to combine several sampling strategies. For example, one could first stratify a given area, then, for each sub-area, adopt a design seemingly suited to the sub-population sampled (systematic sampling, unequal probability, etc; this will depend on the data available on each sample).
The expressions of the estimators and their statistical characteristics get complicated and cannot even be handled analytically, so that comparisons of complex designs (or even of simple designs) are not contemplated. Utilization of this type of design is a gamble which assumes that efficiency will be greater if one has chosen several designs supposedly fitting the manner of variability of the sub-populations to which they are applied.
This final section summarizes the analytical stages helpful to the user in choosing the best design category to meet his or her objective (see Box 49).
Incorporating the data. As the above paragraphs emphasize, it is essential to examine whether there are existing dummy variables. Where these are available prior to sampling, one of two strategies must be chosen. They are either incorporated into the design, or during the estimation stage. The choice is guided by the nature of the variable and the assumed or known extent of the link with the variable of interest. Where they are not available, obviously the person doing the sampling will try to measure the least expensive and most informative variables.
Modelling the constraints. The variance of the estimator is a decreasing function of sample size. For a given design, increasing the size of the sample will increase the exactitude of the estimator and accordingly the cost of the inventory (in both time and money). A good guideline for selecting a sampling plan is the ratio between cost and degree of exactitude, also called efficiency. Calculating this ratio implies that the costs of observing population units can be quantified (indeed estimated), which includes: measuring the variable of interest, dummy variables and fixed costs (salaries, measuring equipment, data processing, etc.) Theoretically, the next step is to seek a strategy to maximize efficiency.
Evaluate design efficiency. Analytical calculation will not, in most cases, permit a comparison of the respective efficiencies of the designs under consideration. Simulations are thus the correct procedure. First, the distribution of the values of the variable of interest are modeled for all units of the population, then the distribution of the dummy variables, plus costs. Then, for each strategy, a set (universe?) of samples is constituted as a basis for an evaluation of the bias and variance of the estimators. This makes it very arduous to compare several strategies, which is why pre-sampling is strongly recommended. The idea is to gather observations on a few units (themselves chosen in accordance with a probability or other design) which can give some idea of the variability of the phenomenon under study. These data can narrow the range of possible distributions of variables and designs. The correlation between the variables of interest and the dummy variables can also be evaluated. Even without this, pre-sampling serves the purpose of fixing the sampling rate (for a given design). It is therefore of interest, even for this reason alone, to carry out pre-sampling prior to inventory. Considering pre-sampling also implies rethinking the evaluation of efficiency. The cost of pre-sampling must be included in the inventory costs, and, there again, the strategy issue reappears in terms of efficiency! What should be the size of the pre-sample, and what design should be used for it? We believe it is essental to have quality data before proceeding to the inventory, and therefore, costing it. If the decision is made to keep the same design, one part of the inventory will already be in place. If not, one should aim for equal or greater exactitude at comparable cost, as the plan selected should in theory be more efficient, and hence less expensive, offsetting the cost of the pre-inventory.
Assessment methods for non-wood forest products In the 1990s, interest mounted in non-wood forest products. Now no longer considered minor items, inventorying or assessing them became an issue. Research done in this field gives us a springboard for the debate on how to inventory Trees outside forests. Wong (2000) reviewed non-wood forest product assessments and their constraints from the biometrical and statistical standpoints. The biometrical quality of the studies was judged by the following two criteria: bias in the sample design (random or systematic), and sample size. According to Wong (2000), only 38 percent of the studies reviewed were biometrically sound; 35 percent used subjective sampling, usually the selection of plots on sites deemed to be « representative ». Restricted sample studies (49 percent of the studies drew on less than 20 units) were undertaken by people in the fields of social development or ethnobotany. Recourse to restricted sampling seems to have become common in recent work. Non-wood forest product inventories primarily utilized forestry designs. Wong (2000) deplores the fact that methodologies from other disciplines were not addressed and adapted. The author stresses the near-absence of interdisciplinary research. The main barriers to the development of biometrically dependable designs for non-wood forest products are product diversity combined with their peculiar destribution into scarce and dispersed aggregates. The absence of methodologies suited to such distribution constraints is a challenge that must be met, for both non-wood forest products and Trees outside forests. |
Move from one scale to the next ? One could reframe the question in more statistical terms, as how to move from a local estimation to a global estimation ? While geostatistics offers a good response, it is not at all clear, on the other hand, that the sampling design alone can provide the response. The simplest method is to make a rule of three in order to move from a small domain to a vaster one. The implicit assumption is that the distribution of variables is the same for the two domains. Many geostatistical studies (Cressie, 1991) have shown the reverse, i.e., that variability increased as the domain increased in size. The procedure is therefore likely to produce highly skewed estimates, and under-estimate the variances. A population model (or models in sub-regions) can also be used for the zone in question. The parameters are estimated on the basis of the sample (s). The best sampling design in this case would be multi-stage or multi-phase sampling, or even systematic sampling, where the absence of periodicity of the variable is a sure thing.
Validation: a necessary step. One cannot generally know whether the sampling design and the size of the sample are suitable. It would, however, be of interest to be able to truly assess to what extent the sampling design suits the objective at hand. There are several conceivable procedures for this. One could increase the size of the sample so as to cover a greater (eventual) variability, and then utilize re-sampling methods (Davison and Hinkley, 1997), or cross- validation methods (Droesbeke et al., 1987). One might also choose a sample with certain sub-samples from other sampling designs, provided some carefully chosen units were subsequently added. For example, one might make a stratified probability sampling which would also permit cluster sampling.
In theory, many small plots (sampling unit) are better for achieving greater exactitude, at the same sampling rate, than a few large plots, but efficiency does not follow this theory (figure 6). There is an optimum plot size which will depend, in particular, on local travel and staff costs.
However, the sample observed for each plot must be representative of the population under study. For example, can a single tree represent treed parkland?
This constraint implies two things:
For the shape of the sampling units, theory recommends circular plots, which have the fewest trees on the edge of the plot with respect to other shapes of equal area. Obviously, though, the circular shape is not suitable for the linear geometry of tree systems such as hedges, wind-breaks, rows of trees....for which long rectangular plots are preferable. Circular plots are also not always easy to set up in practice.
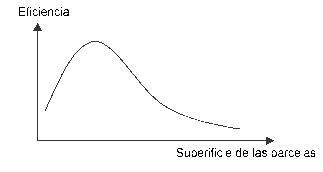
Figure 6: Evolving efficiency as a function of plot size. Efficiency. Area of plots.
3 Or more than one -- to make it simple we will measure just one item. Where more than one parameter is estimated on the basis of more than one variable, we need to remember that it is hard if not impossible to select an ideal sampling design for all parameters to be estimated.
4 We work only with finite populations (made up of a countable set of elements), mindful, however, that infinite populations do also exist. They are either very large (such as the number of flies in the world), or uncountable per se, such as the chemical concentration of nitrates in the soil. But by breaking a population down into smaller elements (discrete blocks of soil, for example), we get back to a finite population, which is what statistical tools are basically designed to deal with.
5 The vocabulary used here is taken from statistics as that is more general. The sample, for instance, will be called a survey or sampling in the socioeconomic field, and an inventory in the natural sciences. There will be several formulations as we are drawing on a number of sources for our illustration, but we shall try to use terms common in forestry where possible.
6 With reference to the preceding note, we shall also use the term `sampling plan'.
7 Also called co-variable or concomitant variable: these terms are actually less strict in that they indicate variables that do not necessarily measure the whole population.
8 Inference or estimation.
9 Partition: division of an area into contiguous, non-overlapping units, which form the total area when joined.
![]()
![]()
![]()